AI/ML●Mid
Parseflow, how to parse documents when you're broke
Student-built extraction API competing directly with established players like LlamaParse.
Ship ItBold Bet
bollethegoalie
2022d ago
ProofPudding returns extraction results with explicit links back to the exact page and source text, supports native and scanned PDFs plus DOCX/images, and ships Python/TypeScript SDKs — handy for agents that need auditable facts. It’s a pragmatic product (per-extraction pricing and confidence scores are nice), but the market is crowded; I want clarity on underlying models, real-world accuracy numbers, and how it compares to Document AI/Textract in edge cases.
Backend developers, ML engineers, and teams in legal/finance/compliance who need reliable, auditable document extraction
Student-built extraction API competing directly with established players like LlamaParse.
94.5% accuracy, self-hostable, open source—beats Textract on cost and accuracy.
Offline Ollama + OCR keeps your documents private when cloud APIs won't.
Citation-first RAG drops hallucination risk, but Remove.bg's citations + Perplexity's footnotes already proved this.
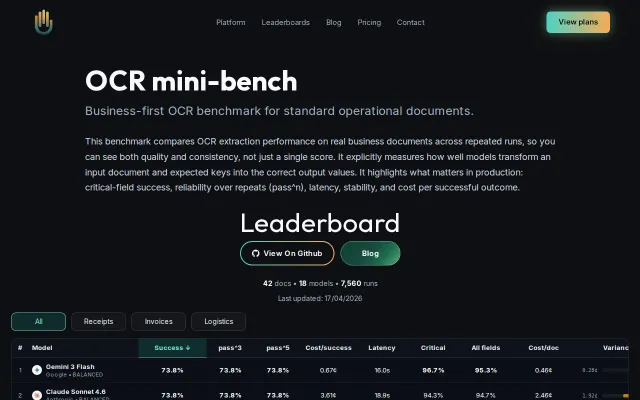
7,560 runs proving cheaper models beat expensive ones on production OCR tasks.
Extracts tracked changes and comment threads when most DOCX parsers only grab text.