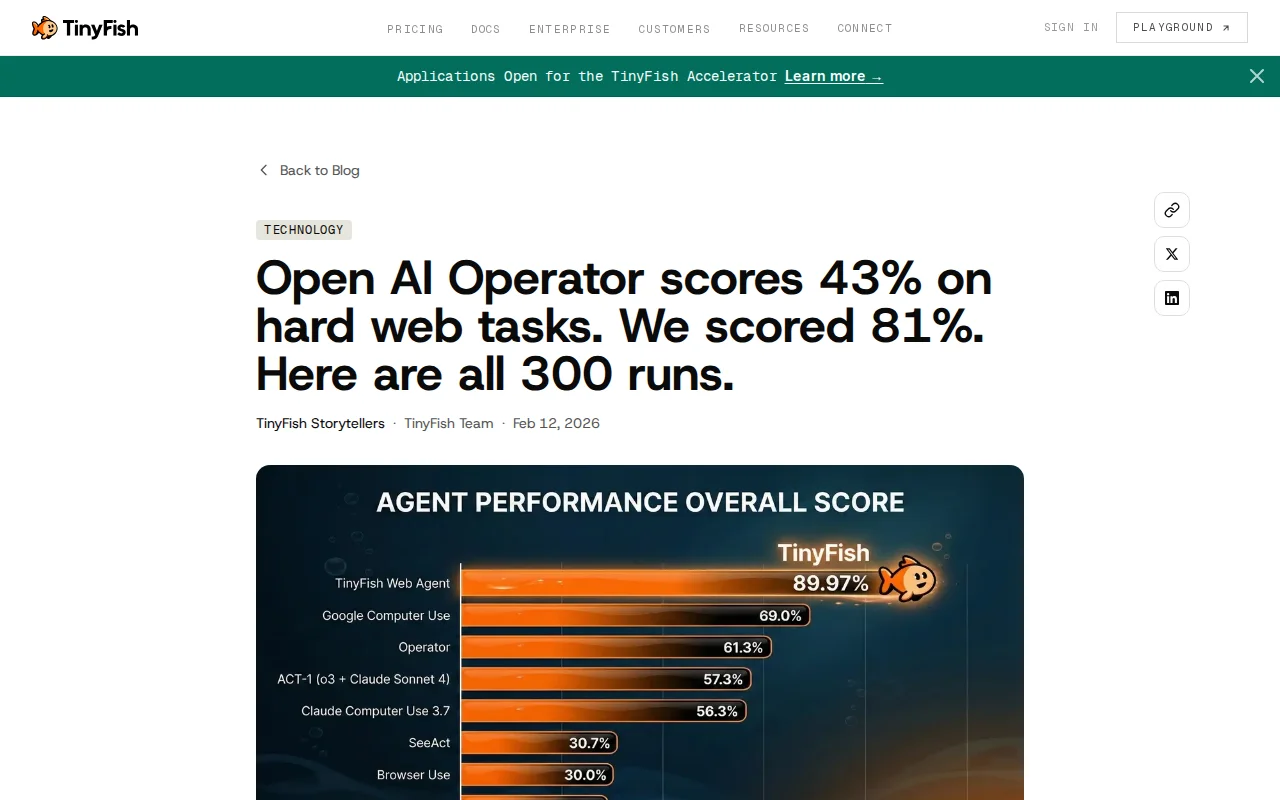
Enterprises need ~90% accuracy to deploy web agents. Until now, no agent has come close on real-world tasks. TinyFish is the first production-ready web agent. Here's the evidence.
Results of hard task scores on Online-Mind2Web (300 tasks, 136 live websites, human-correlated judge):
- TinyFish: 81.9%
- OpenAI Operator: 43.2%
- Claude Computer Use: 32.4%
- Browser Use: 8.1%
Why not WebVoyager like everyone else?
Because it's broken. Easy tasks, Google Search shortcuts, and a judge that agrees with humans only 62% of the time. Browser Use self-reported 89% on WebVoyager — then scored 8.1% on hard tasks here.
We evaluated TinyFish against Online-Mind2Web instead — 300 real tasks, 136 live websites, three difficulty levels, and a judge that agrees with humans 85% of the time. No shortcuts. No easy mode.
The cookbook repo is open source: https://github.com/tinyfish-io/tinyfish-cookbook
You can see all failure task runs form here: https://tinyurl.com/tinyfish-mind2web
Happy to answer questions about the architecture, the benchmark methodology, or why we think WebVoyager scores are misleading.