Developer Tools●●Solid
RunVeto – A Simple Kill Switch for Autonomous AI Agents
Agent cost killswitch solves a real pain, but monitoring infra is crowded.
Solve My ProblemShip It
JDPatel1729
103mo ago
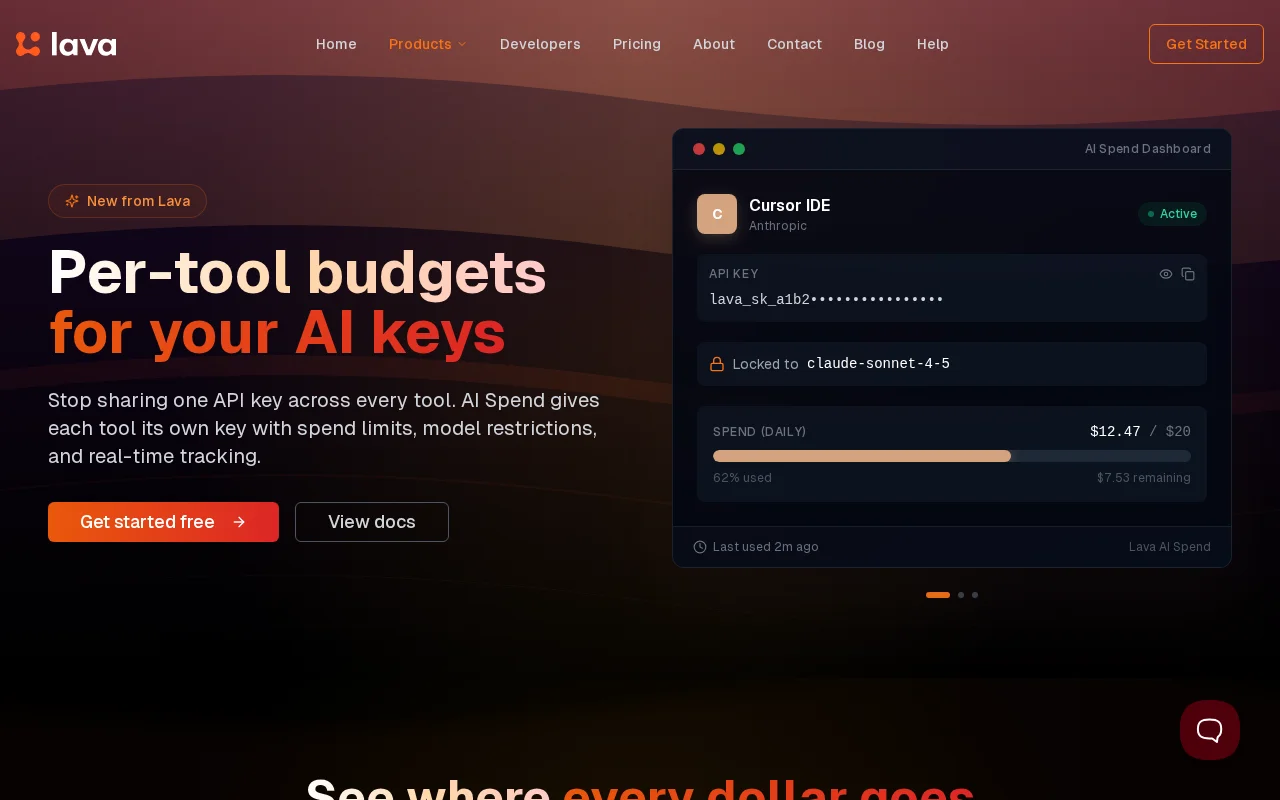
This is the sort of practical infrastructure you actually want after an overnight bill shock: per‑tool isolated keys, cycle-based caps, model locks and instant revoke all enforced by a transparent OpenAI‑compatible proxy. It's smart engineering for a common pain, though it naturally centralizes traffic — so trust, latency and vendor access policies are the tradeoffs to weigh.
Developers, engineering teams, AI ops, and product/tool integrators who use multiple LLM-powered tools and want per-tool cost controls
That was the breaking point, but the real problem had been building for a while. I use tools like OpenClaw and Cursor daily, each hitting various AI providers. But I had no idea what each tool was actually costing me. One shared key across everything, no per-tool visibility, no way to cap spend.
So I built AI Spend into Lava. The idea is simple. Create isolated API keys, each with their own:
- Spend limit (daily/weekly/monthly/total) - Model restriction (lock to a specific model or allow any) - Real-time usage tracking - Instant revoke
It works as a transparent proxy. Your tools point to a single OpenAI-compatible endpoint. Lava validates the key, checks the spend limit and model restrictions, then forwards the request to the right provider. Spend is tracked per key per cycle. When a key hits its limit, requests are rejected until the cycle resets. Under the hood it translates requests across 38+ providers (OpenAI, Anthropic, Google, Mistral, DeepSeek, etc.), so anything that works with the OpenAI API works with this. No SDK changes.
Would love to hear how others are handling AI cost control, especially if you're running agents in production.
Agent cost killswitch solves a real pain, but monitoring infra is crowded.
Kill switch fires mid-loop at dollar ceiling before the bill lands.
Vault proxy injects credentials at the network layer so agents never touch your keys.
Macaroon-based budget enforcement for AI agents—fills a real economic governance gap.
Deterministic Go governor halts runaway agents at budget with HTTP 402.
Iterator-first design beats black-box frameworks like LangChain for debugging.