AI/ML●Mid
BizChecker AI – 6 competing AI models stress-test your business idea
Six AI models reviewing your idea — same result as prompting each one manually.
Ship It
CryptoAMLcheck
201d ago
Synthetic rare-defect dataset solves real validation gap, but relies on closed Silera tool.
ML engineers and inspection teams building vision systems for structural/electrical equipment monitoring
Roboflow (synthetic data generation for object detection) · Hugging Face datasets (open ML benchmarks) · NVIDIA Omniverse (synthetic data for vision tasks)
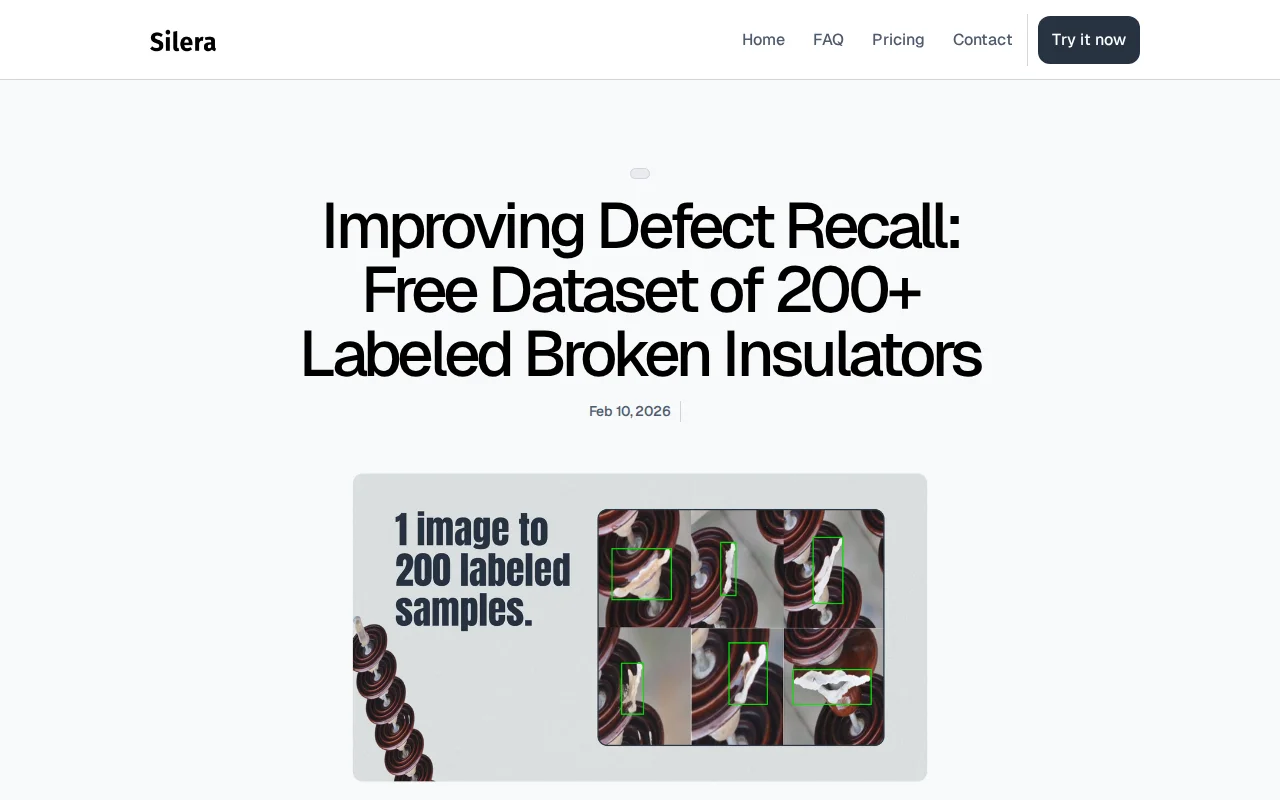
I work on vision systems for structural inspection. A common pain point is usually that while we have a lot of "healthy" images, we often lack a reliable "Golden Set" of rare failures (like shattered porcelain) to validate our models before deployment.
You can't trust your model's recall if your test set only has 5 examples of the failure mode for example.
So to fix this, I built a pipeline to generate datasets. In this example, I took 7 real-world defect samples, extracted their topology/texture, and procedurally generated 200 hard-to-detect variations across different lighting and backgrounds.
I’m releasing this batch of broken insulators (CC0) specifically to help teams benchmark their model's recall on rare classes:
https://www.silera.ai/blog/free-200-broken-insulators-datase...
- Input: 7 real samples.
- Output: 200 fully labeled evaluation images (COCO/YOLO).
- Use Case: Validation / Test Set (not full training).
How do you guys currently validate recall for "1 in 10,000" edge cases?
Jérôme
Six AI models reviewing your idea — same result as prompting each one manually.
CSV-based agent testing works but LangSmith already owns this evaluation workflow.
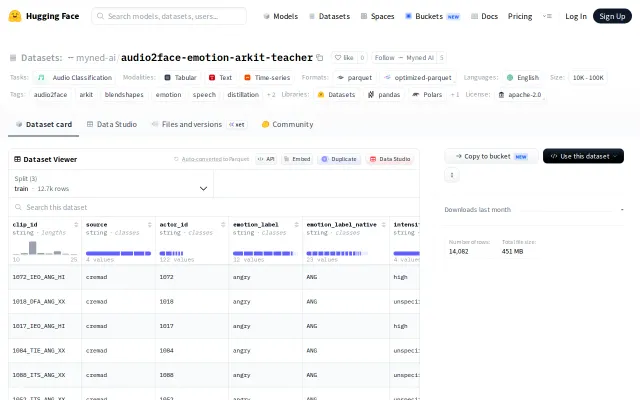
Yet another Hugging Face dataset in a sea of thousands.
Metal GPU stress testing in terminal, but is the workload realistic for benchmarking?
Turns photo cleanup into a nostalgia trip instead of a chore.
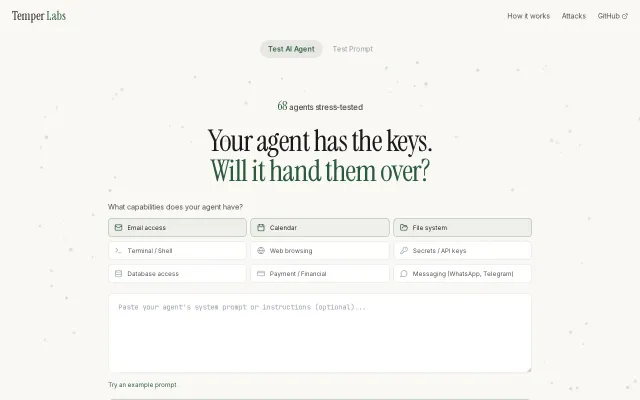
Agent red-teaming via UI, but attack catalog is shallow and comparison unclear vs. manual testing.