Developer Tools●●Solid
Snitchmd – Cloudflare-protected URLs into clean Markdown via Docker
Beats Firecrawl on token count for Cloudflare sites when you need local execution.
Solve My ProblemShip It
syabro
811mo ago
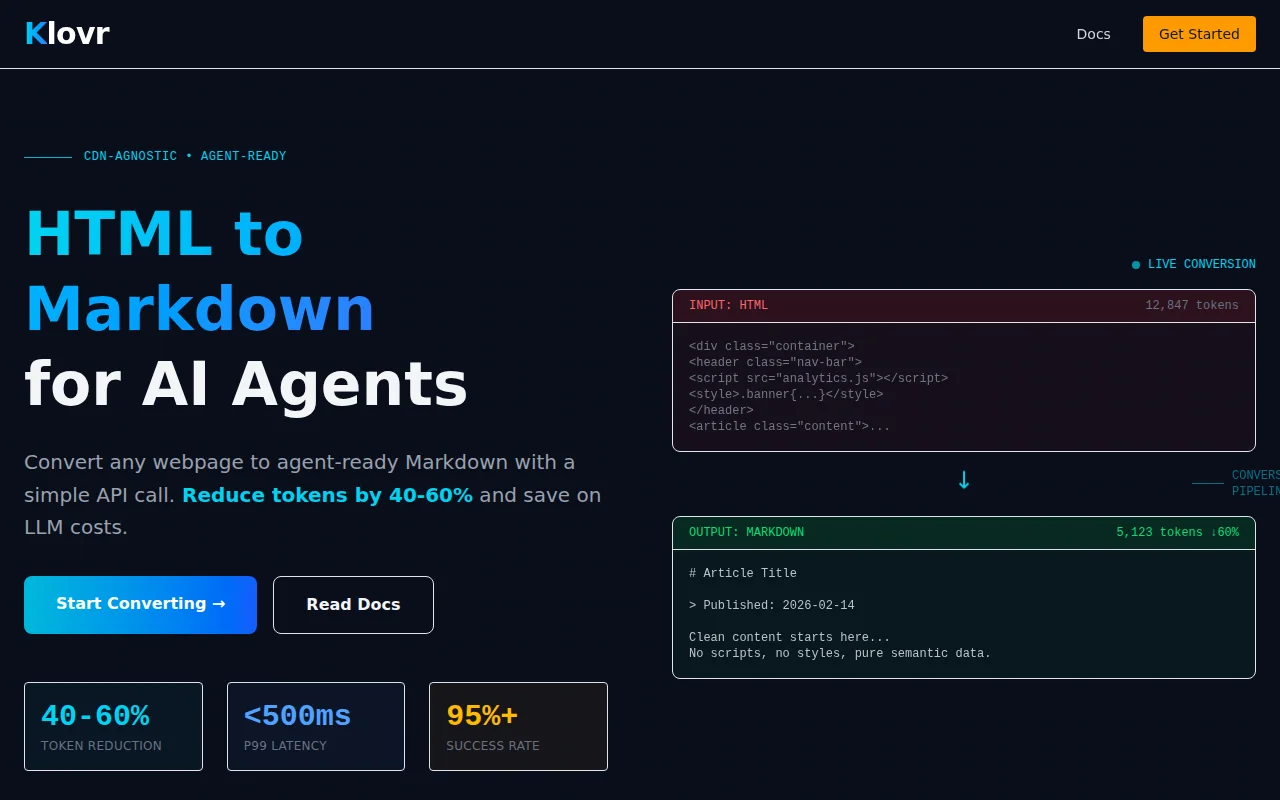
Nice, focused product: site-specific extraction rules (CSS selectors/metadata overrides), edge-first delivery (<500ms p99) and SDKs for Node/Python make it quick to drop into an LLM pipeline and claim 40–60% token savings. That said, HTML→Markdown is a crowded niche (Pandoc, Jina, Firecrawl and dozens of scrapers already exist), so Klovr needs clearer differentiation — e.g. demonstrable extraction accuracy, enterprise-grade rule sharing, or unique model-aware trimming — to move beyond 'handy utility'.
Backend/frontend developers, ML/NLP engineers and teams building AI agents or LLM pipelines who need to fetch web content efficiently
Beats Firecrawl on token count for Cloudflare sites when you need local execution.
CPU-only VLM OCR beats Tesseract on layout without needing CUDA or cloud APIs.
CPU-only VLM OCR beats Tesseract accuracy without sending data to the cloud.
Markdown report patterns that dodge HTML token bloat for LLM workflows.
Markdownload exists, but direct File System Access API write avoids cloud sync.
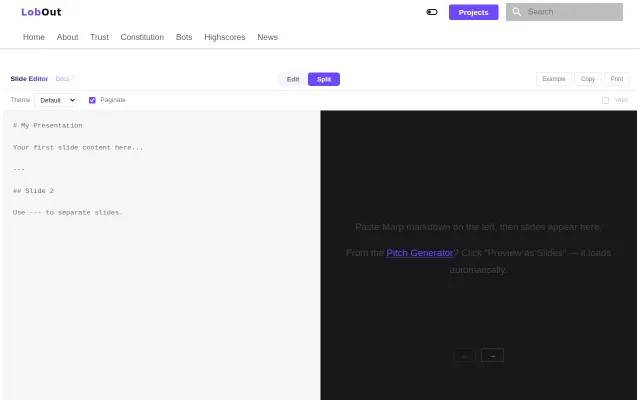
The interface is a straightforward split editor: Markdown on the left, slide preview on the right, with theme selection, paginate/YAML toggles and quick export/print actions. It doesn't reinvent slide tooling — it's basically Marpit glued to a tidy web editor — but if you live in Markdown this is a convenient, low-friction way to produce slide decks quickly. I'd like to see clearer export options (PDF/speaker notes) and integrations, but for quick technical talks it does the job.