AI/ML●Mid

Think Fu – Metacognition as a service
Prompt engineering library dressed up as metacognition infrastructure.
Big BrainNiche Gem
georgestrakhov
302mo ago
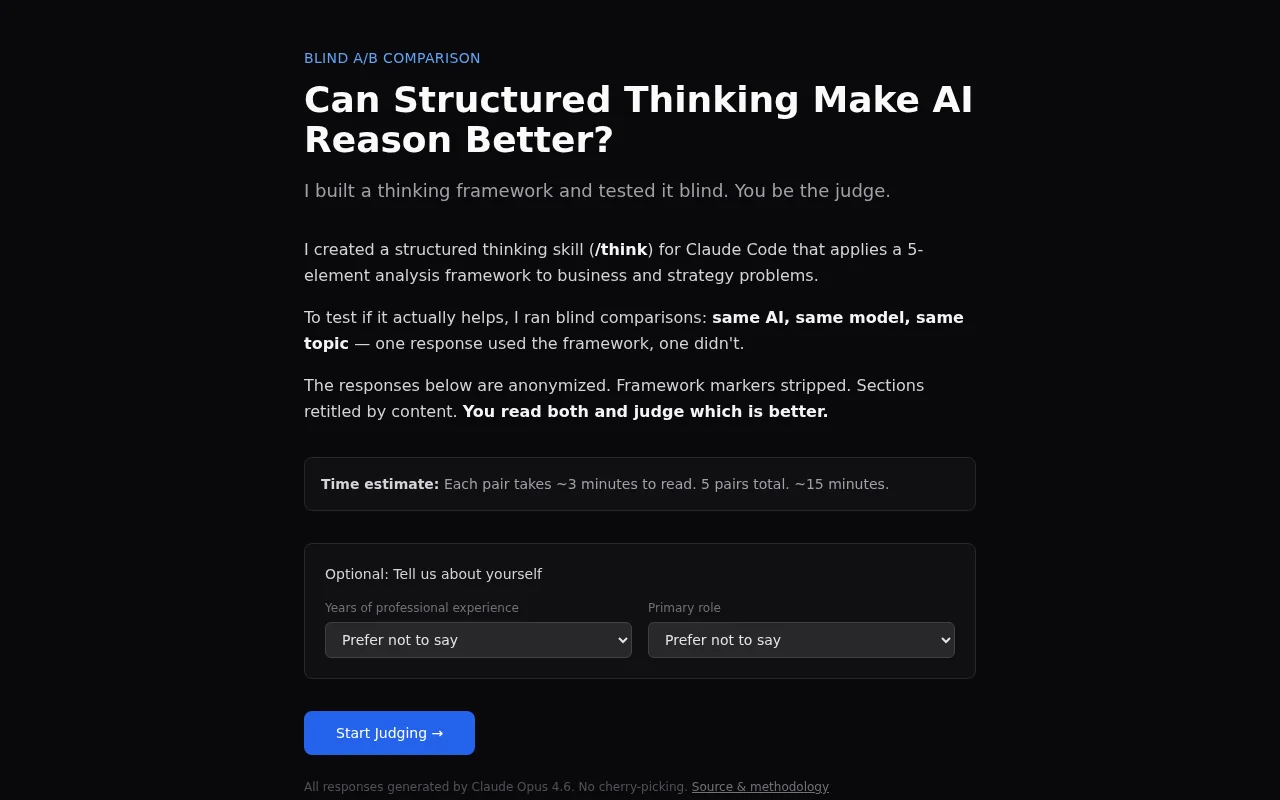
The site pairs a concrete 5-step rubric (ground facts, stress-test failures, reframe, trace implications, audit reasoning) with a blind A/B UI so humans can judge if structure actually helps an LLM — neat experimental rigor that most prompt experiments skip. It’s clever and pragmatic, but the idea isn’t brand-new (it’s essentially formalized chain-of-thought prompting) and the scope is narrow (Claude-only, small sample of topics).
Product managers, founders, strategy consultants, prompt engineers and AI hobbyists who want clearer, more rigorous LLM reasoning
/think wins ~69% of comparisons overall Risk coverage is the clearest advantage (17-2 across all tests) — it consistently surfaces failure modes the organic response misses Decision impact is nearly even — organic Claude is often more actionable for practical problems Novel insight is mostly a wash — both find similar core insights, just different ones No decisive gaps in either direction. The advantage is depth and rigor, not dramatic superiority
Honest limitations:
All judges so far are AI. The whole point of publishing the blind test is to get human validation. ~21 comparisons is a pattern, not statistical significance Anonymization isn't perfect — /think responses have stylistic tells (confidence assessments, "what would change this conclusion" sections) The framework costs significantly more tokens
The skill itself is a recursive learning agent — it persists what it learns to a .think/ directory and loads that context in future sessions. Over time it builds project-specific knowledge. It also used its own framework to diagnose and fix its own weaknesses after the first round of testing. Everything is open source: https://github.com/bengiaventures/effective-thinking-skill I'd genuinely like to know if the blind test matches what the AI judges found, or if humans see something different. Takes about 15 minutes.
Prompt engineering library dressed up as metacognition infrastructure.
Curated prompt library when dozens of skill packs already exist for Claude.
Persistent memory across sessions lets it remember what you tried six months ago.
Structured eval workflow for Claude Code when LangSmith and Braintrust already exist.
Prompt wrapper for Grug Brained Developer wisdom, no technical implementation beyond instructions.
155 decision frameworks in CSV, BM25-ranked for your problem—structured thinking at prompt time.