Developer Tools●●Solid
CacheLens – Local-first cost tracking proxy for LLM APIs
Local budget caps block requests before provider dashboards even update the bill.
Solve My ProblemCozy
stephenlthorn
203mo ago
Open-source AI Cost Intelligence Platform — smart routing, semantic cache, waste detection, prompt optimization
Proxying every LLM call to log tokens is the right kind of blunt instrument — you get per-developer, per-model cost telemetry immediately. Smart routing and the built-in semantic cache (claims 45–80% savings) are the most useful ideas here, but the default SQLite backend and admin/admin creds scream MVP rather than production-ready scale.
ML/AI teams, backend developers and infra engineers who need real-time cost observability for LLM usage (engineering managers, SREs, and startup teams running experiments)
I built TokenMeter after seeing how unpredictable LLM costs become as usage scales.
Most teams optimize prompts but lack real-time cost observability.
This project tracks token usage and exposes cost insights to help AI teams stay financially aware.
Would appreciate feedback on architecture and missing observability features.
Thanks.
Local budget caps block requests before provider dashboards even update the bill.
Wire-protocol proxy means zero code changes to existing LLM clients.
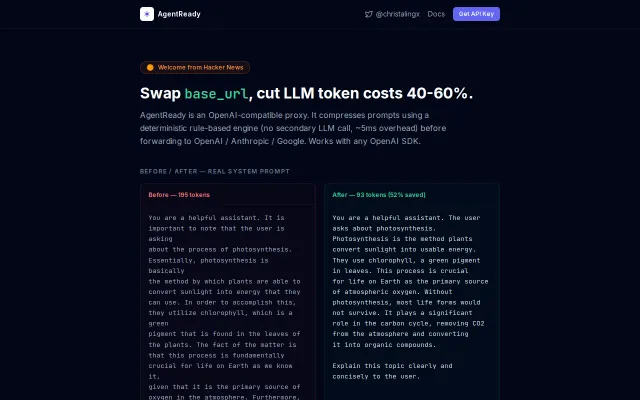
Drop-in proxy that cuts GPT token costs 40-60% without changing app code.
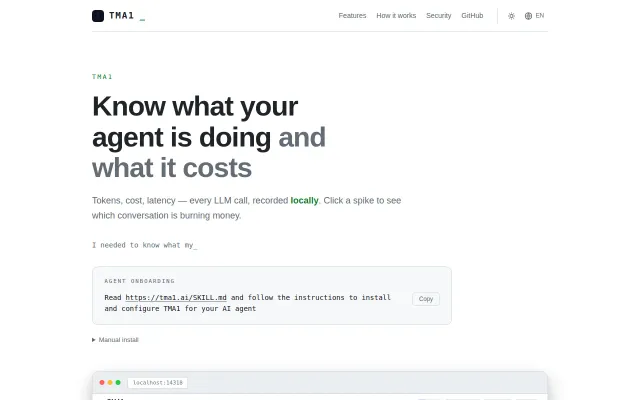
Local-first agent observability without cloud signup — LangSmith alternative that keeps data on your machine.
Control plane with token budgets and MCP rules goes beyond passive observability.
Agent-native observability with DAG topology when LangSmith and Langfuse miss multi-agent flows.