AI/ML●Mid
The Global Llms.txt Index
Searchable directory for llms.txt files when general search engines could index these.
Ship It
olex-green
2011d ago
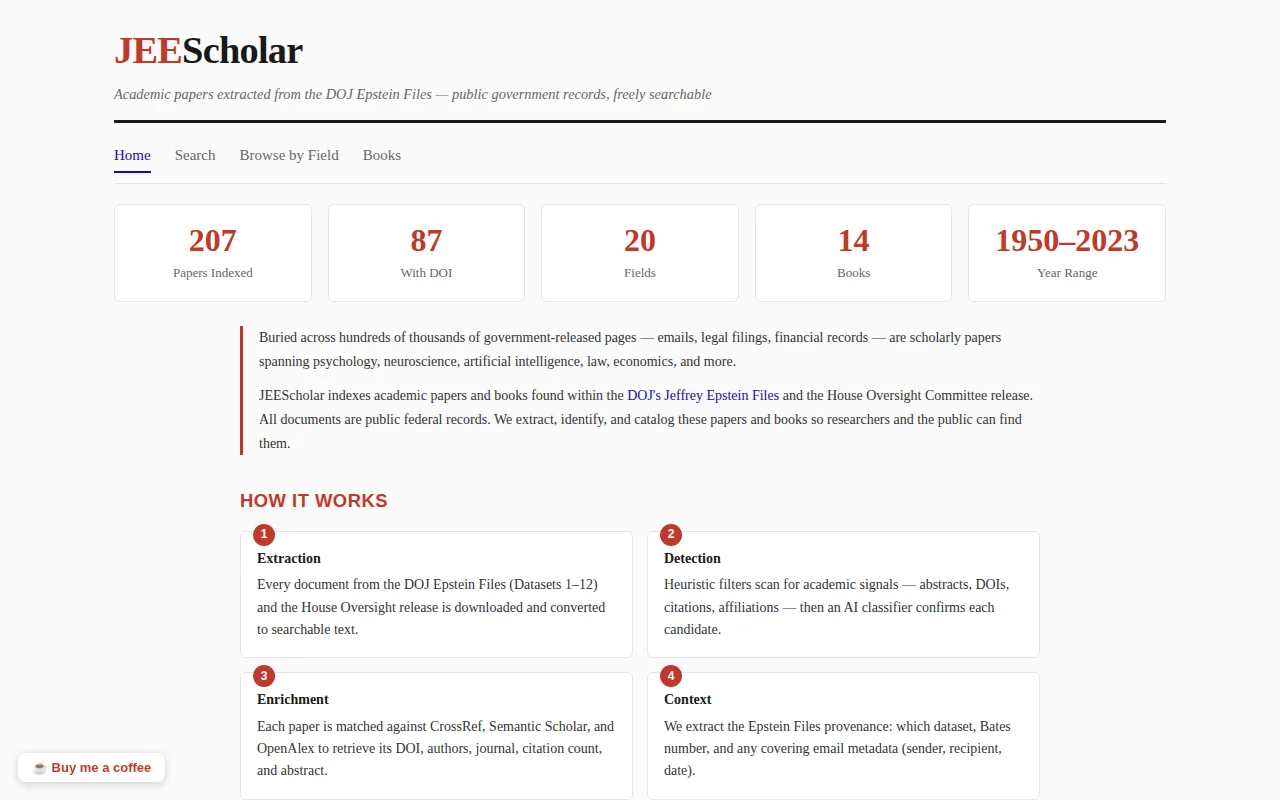
207 papers buried in government records, now searchable with full context extraction.
Researchers, academics, journalists, public records investigators
Document indexing projects (e.g., OpenCorporates, Internet Archive Scholar) · Academic metadata aggregators (CrossRef, Semantic Scholar) · FOIA document databases (PACER, SEC Edgar)
I don't know, thought it was interesting to see what this dude was reading. You can check it out at jeescholar.com
Pipeline: 1. Downloaded all 12 DOJ datasets + House Oversight Committee release 2. Heuristic pre-filter (abstract detection, DOI regex, citation block patterns, affiliation strings) to cut noise 3. LLM classifier to confirm and extract metadata 4. CrossRef and Semantic Scholar APIs for DOI matching, citation counts, abstracts 5. 87 of 207 papers got DOI matches; the rest are identified but not in major indexes
Stack: FastAPI + SQLite (FTS5 for full-text search) + Cloudflare R2 for PDFs + nginx/Docker on Hetzner.
The fields represented are genuinely iteresting: there's a cluster of child abuse/grooming research, but also quantum gravity, AGI safety, econophysics, and regenerative medicine. Each paper links back to its original government PDF and Bates number.
For sure not an exhaustive list. Would be happy to add more if anyone finds them.Searchable directory for llms.txt files when general search engines could index these.
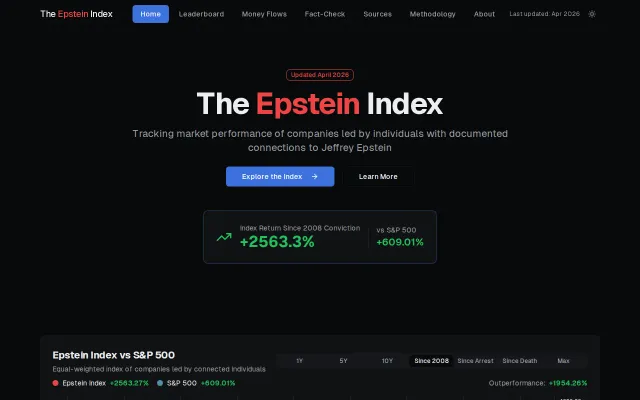
Provocative data journalism showing Epstein-linked companies outperformed S&P by 1954% since conviction.
Curated YouTube index when the channel's own playlists already exist.
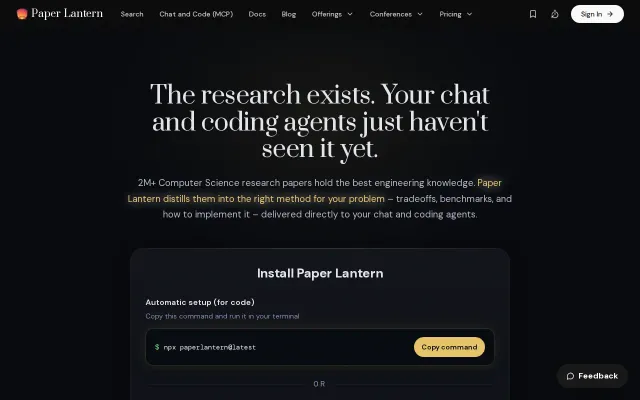
Coding agents miss research knowledge; this surfaces 2M+ papers with benchmarks.
Useful directory for MCP discovery, but it's just a curated list with search — no novel tech.
FFmpeg binary search with permanent mirroring so CI/CD never breaks.