AI/ML●●Solid
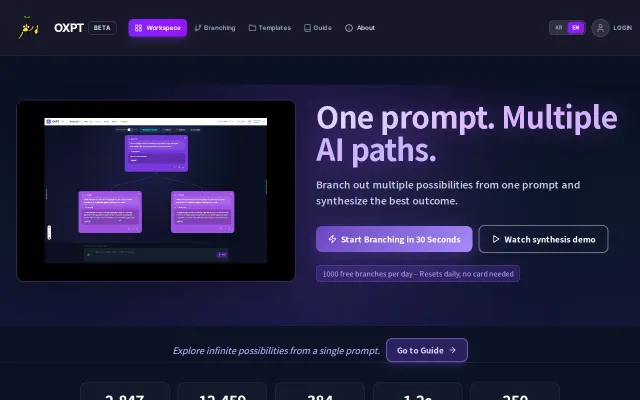
OXPT – Visual branching canvas for prompt versioning (Korean support)
Beautiful node-based UI for prompt branching, but prompt iteration tools already exist everywhere.
Eye CandyCrowd Pleaser
macnorton
103mo ago

Steganography-based A/B testing for prompts sidesteps trace ID plumbing entirely.
LLM app developers, prompt engineers, AI product teams
Mixpanel · Amplitude · PostHog
I just built the first version of Nebark, an A/B testing platform for LLM system prompts. It aims to solve a very specific pain point: tracking prompt performance without forcing developers to wire trace IDs all the way through their backend to their frontend.
The Problem If you want to know which system prompt variant generates better user feedback (upvotes, downvotes, or copy-to-clipboard events), the standard approach is intrusive. You have to generate a trace ID in your backend, pass it down to your client, attach it to your UI components, and send it back to your analytics DB. It creates friction and litters your API responses with telemetry metadata.
The Solution: Context Hashing We decoupled the telemetry entirely using what we call "Context Hashing" to bridge the backend and frontend asynchronously.
Here is how the architecture works:
The Proxy (Backend): You point your OpenAI baseURL to our gateway. We intercept the request, inject Variant A or B of your system prompt, and stream the response back. Once the stream closes, our proxy calculates a unique cryptographic hash based on the interaction's content and stores it as a blind trace.
The SDK (Frontend): A lightweight vanilla JS script watches the DOM. It smartly waits for the AI's response to finish streaming and rendering on the screen. It then extracts the visible text and calculates the exact same unique hash locally, without intercepting any network traffic.
The Match: The SDK injects the feedback UI (/). When a user clicks, the frontend sends this calculated Hash and a local Session ID to our DB. We match this Hash against the Proxy's traces to attribute the vote to the correct prompt variant.
Why it’s interesting
Zero Backend Config: You only change the base URL. The backend remains completely unaware of the A/B test or the telemetry.
Semantic Caching Immunity: If your backend uses Redis to serve a cached response and skips our Proxy, the frontend will generate a Hash that doesn't exist in our DB. It naturally prevents skewed A/B data from cached hits.
The Edge Cases (Where I need your feedback) The biggest risk with DOM hashing is hydration/rendering discrepancies. If a client's frontend uses an aggressive Markdown parser that strips out specific characters before rendering the text, the frontend hash won't match the proxy hash. We built a strict internal normalization engine on both ends to mitigate this, but it is an ongoing challenge.
I’d love to hear your thoughts on this architecture. Is there a glaring edge case with DOM extraction or SSE proxying that I’m missing? Its free for now. Tear it apart.
Beautiful node-based UI for prompt branching, but prompt iteration tools already exist everywhere.
Tackles persona collapse with architecture, but lacks proof-of-concept or working implementation.
Daily writing prompts with community responses; feature-complete but not differentiated.
LLM-native task runner mixing prose and shell, but Make/Just already work and GitHub Actions covers CI/CD.
Static scanner catches prompt injections in code before runtime, unlike runtime guards.
Fills genuine pain: 'found via ChatGPT' can't be measured with old SEO tools—self-host or SaaS.