Developer Tools●Mid
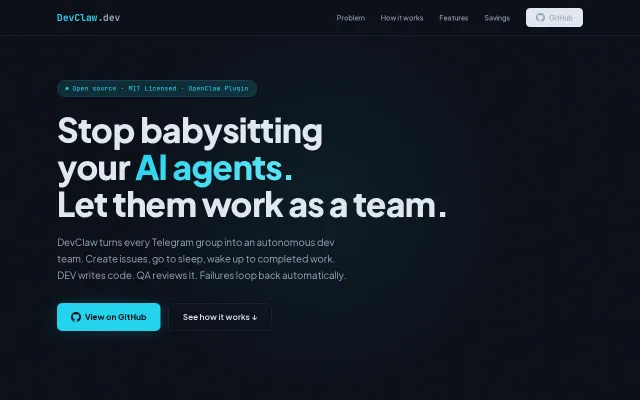
Stop Babysitting Your Agents – Let Them Work as a Team
Replaces agent orchestration with deterministic code, but 'multi-agent dev team' space is crowded.
Solve My ProblemShip It
laurentenhoor
103mo ago
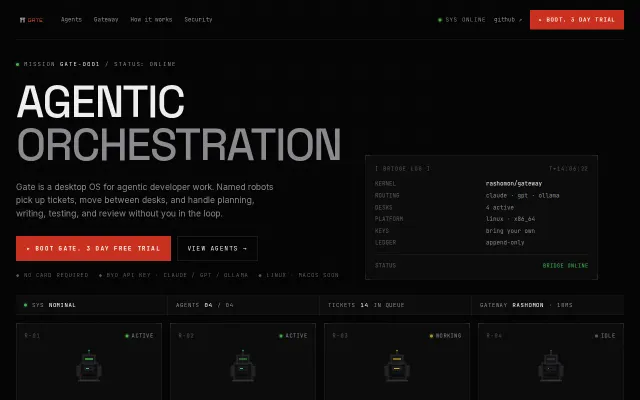
🐯Autonomous dev orchestration that never stops. Failures still converge to completion.
Multi-agent dev orchestration with judge + recovery loop, but core value depends on agent quality upstream.
Teams running autonomous AI coding agents at scale, CI/CD engineers, AI orchestration builders
LangGraph · CrewAI · Anthropic's multi-turn agent patterns
So I asked a different question: what if the system was designed around the assumption that agents WILL fail, and the job of the infrastructure is to never let that failure become a dead end?
openTiger is a "non-human-first" orchestration system that runs multiple AI agents in parallel — planner, workers, testers, judge — each with a dedicated role. The planner decomposes requirements into tasks, the dispatcher fans them out to worker agents concurrently, and the judge evaluates results and feeds back rework decisions. It's not one agent doing everything; it's a pipeline of specialized agents running simultaneously.
The entire architecture is built on one principle: no state is terminal. Every failure is a blocked state with a reason, and every reason has a recovery path. If the same failure repeats, the system escalates to a different strategy instead of retrying the same thing.
The interesting philosophical bit: optimizing for recovery turns out to be more effective than optimizing for first-attempt success. When you stop fearing failure, you can let agents be more aggressive.
Early stage, lots to improve. Feedback and contributions welcome.
Replaces agent orchestration with deterministic code, but 'multi-agent dev team' space is crowded.
Sandboxed AI agents coordinate code tasks locally without sending data to cloud.
Multi-agent DAG for code execution, but early-stage and dependency-heavy setup required.
DAG-based agent swarms with spec generation from codebase beat prompt chaining, but long-term reliability unproven.
Multi-project agent orchestration with 70% token savings via model tiering and session reuse.
Claude agents solving GitHub/Linear issues autonomously—production-grade, 4K LOC tested, real demo.