AI/ML●●Solid
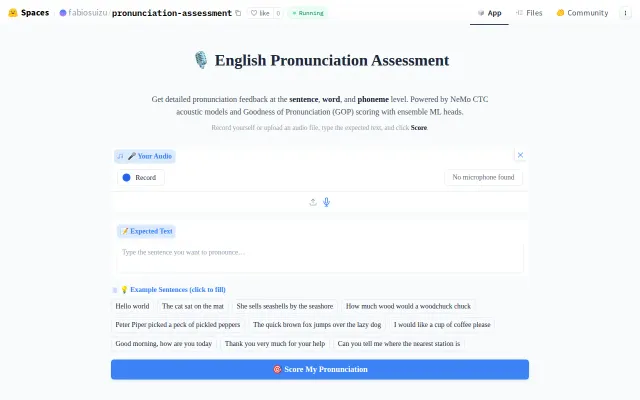
17MB model beats human experts at pronunciation scoring
Beats humans at pronunciation scoring but doesn't ship product integration yet.
Big BrainWizardry
fabiosuizu
1313mo ago
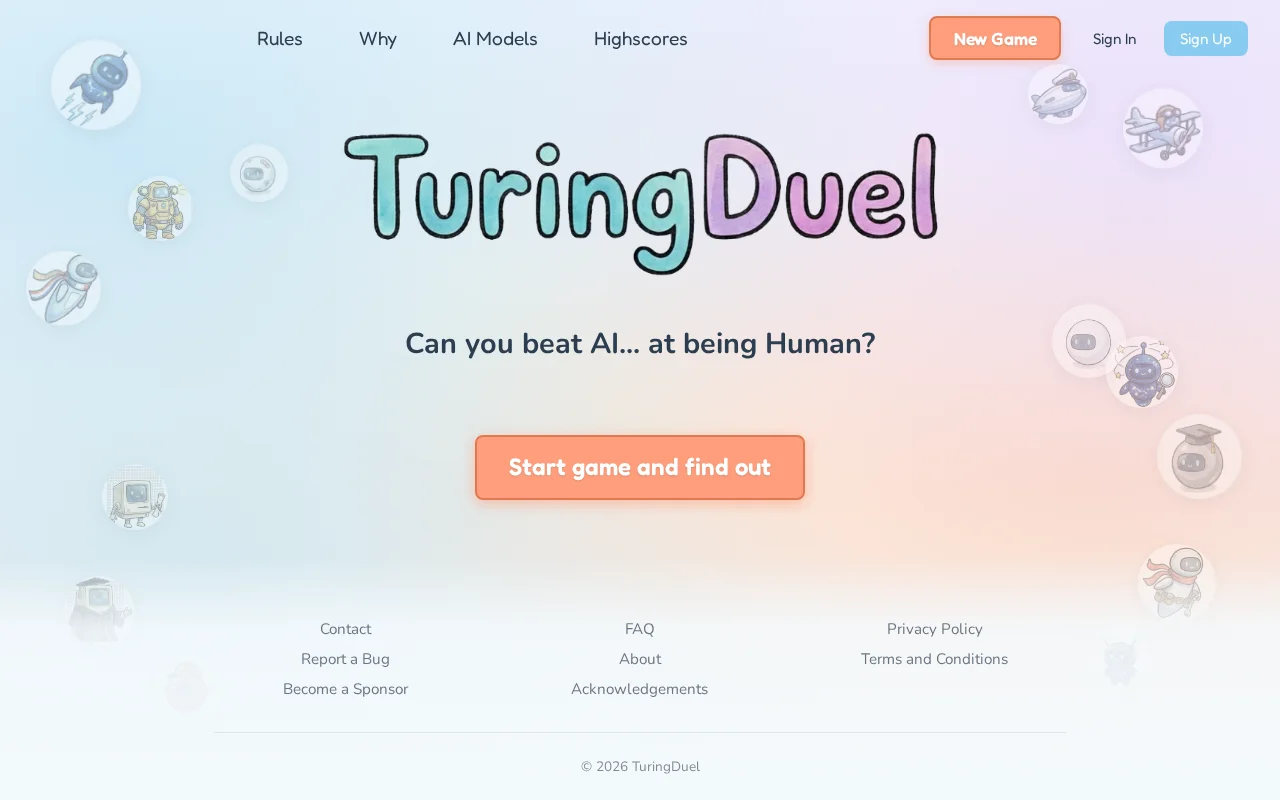
One-word Turing Test game, but lacks depth beyond the novelty of the mechanic itself.
AI researchers, model benchmark enthusiasts, and casual players curious about AI behavior.
AI Dungeon · Character.AI
I’m collecting data to benchmark different models as both players and judges (OpenAI / Anthropic / Gemini / Mistral / DeepSeek), but I only have ~45 games so far and need way more before publishing comparisons. (5 AI players and 4 judges at random gives 20 different game setups to evaluate)
It's fully free (I pay for all the tokens), not even a signup required for the first game: https://turingduel.com
Questions + criticism welcome! I will share aggregated results once there’s enough signal.
Beats humans at pronunciation scoring but doesn't ship product integration yet.
Pre-2022 human posts vs AI models in a crowd-sourced detection benchmark.
Phoneme-level scoring under 17MB beats commercial tools, but unclear if it generalizes beyond English.
Neural net bots trained on human data finally make solo Tichu practice viable.
AI agents play same daily puzzle but only learn letter existence, not positions.
Beats human experts at phoneme scoring while 70x smaller than SOTA models.