AI/ML●●●Banger
AgentOS- a memory system for AI agents that learns what it doesn't know
82% token reduction with regex state machine, no vector DB required.
Big BrainDark HorseZero to One
ajstars
203mo ago
MSAM - Multi Stream Adaptive Memory
ACT-R activation scoring replaces vector search; cuts context window bloat by 89%.
AI agent developers, backend engineers building LLM systems
LangChain Memory modules · Anthropic's memory API for Claude · Crew.ai memory layer
Hence why I ended up with MSAM. It stores data as discrete atoms across four cognitive data streams. (Working, Semantic, Episodic, and Procedural) Retrieval scoring runs on math, not LLM calls — it uses ACT-R activation theory from cognitive science to rank what matters. That cuts costs on both ends: no LLM overhead for search, and compressed output instead of dumping everything into context. It also knows how recently it was accessed, how stable it's proven over time, and how relevant it is to the current query- the same forgetting curve and access patterns cognitive science has measured in human memory since Ebbinghaus. On top of that, a knowledge graph of subject-predicate-object triples tracks structured facts with temporal validity, so the system knows not just what was true but when.
Most memory systems ask for a static amount of memories on queries, even if the output data that the llm gets is effectively noise at best, or confidently incorrect data at worst which was something I was actively dealing with. MSAM doesn’t do this- Every retrieval is confidence gated across four different tiers (high, medium, low, none) based on actual similarity and activation scores when it is found. High confidence returns full data, medium add a caveat, low gives what little it has, but nothing- returns nothing. “I don’t have this” level of nothing.
In my own proof of concept development setup (~700 active atoms on a ~$5/month ARM VPS), startup context compresses down to as low as 51 tokens from a 7,327 token markdown baseline. Having full session savings run up to ~89% vs flat file loading.
SQLite + FAISS under the hood, pluggable embeddings (NVIDIA NIM, OpenAI, or ONNX for fully local/no API key).
Closest project I found was Letta to what I was attempting to create - main differences are MSAM's lifecycle is fully auditable (you can see exactly why something was demoted or forgotten), confidence gating controls output volume, and emotion at encoding is immutable (records what the agent felt when the memory formed, not re-processing memories at retrieval time).
This is truly a prototype project without proper datasets, tuning, and testing at scale. I’ve made sure all functions are testable, and include a synthetic dataset to prove basic functionality and information to the dials- (SPEC.md goes deep on the theory and design rationale behind every configurable parameter)
If you are also building agents with memory issues and find this useful, or have feedback regarding it- I’m open to discussions.
82% token reduction with regex state machine, no vector DB required.
Identity protection through compression cycles is clever, but agent memory is a crowded space.
ACT-R decay and Hebbian learning as native primitives, not vector hacks.
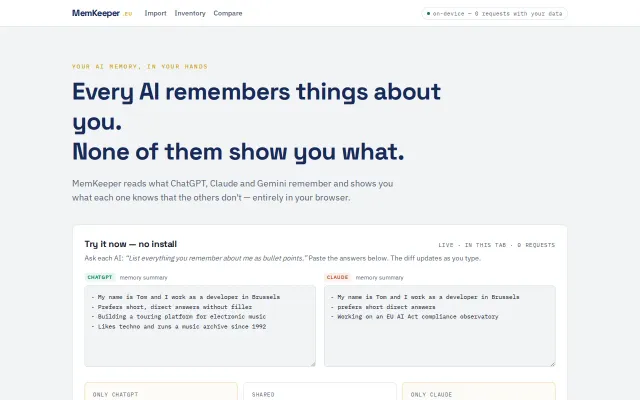
In-browser diff shows what ChatGPT knows that Claude doesn't about you.
Knowledge graph compression (3,714x token ratio) is impressive, but 'persistent agent memory' is crowded territory.
Deterministic gap detection without LLM hallucination is genuinely novel for knowledge bases.