Finance●●Solid
165k lines, 9 days, one dev I built what ICE sells to hedge funds
Reverse-engineered ICE's hedge fund product in 9 days, but unproven vs. established screeners.
Big BrainRabbit Hole
Shmungus
303mo ago
F5Bot but it learns your signal vs keyword matching noise.
Founders, product managers, and marketing teams launching SaaS
F5Bot · Feedly AI · Punchmetrics
I had F5Bot set up for keywords, but it was sending me 50+ alerts a day — mostly irrelevant. I'd spend 20 minutes triaging to find 2 threads worth responding to. The problem wasn't lack of monitoring, it was lack of signal.
Bruce is different: instead of matching keywords, it scores every item 0-100 against your product context, ICP, and competitor list. It understands why something is relevant, not just that a keyword appeared.
The part I'm most excited about: it learns. Every time you act on a signal or dismiss one, Bruce adjusts. By week 2, it's surfacing very different (better) things than week 1.
What it monitors: Reddit, Hacker News, RSS feeds, ProductHunt, and anything with an RSS endpoint via RSSHub (YouTube channels, newsletters, etc.)
Stack: Next.js 15, PostgreSQL, Drizzle, Better Auth, my self-built AI runtime, RSSHub.
Live at https://smartbruce.com
Happy to answer questions about the scoring model or architecture.
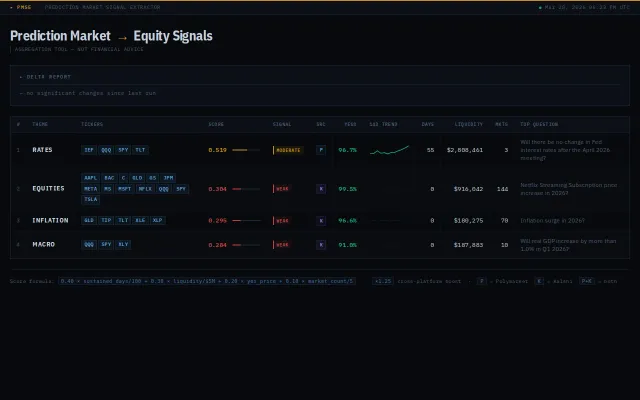
Reverse-engineered ICE's hedge fund product in 9 days, but unproven vs. established screeners.
Transparent scoring formula beats black-box prediction market aggregators.
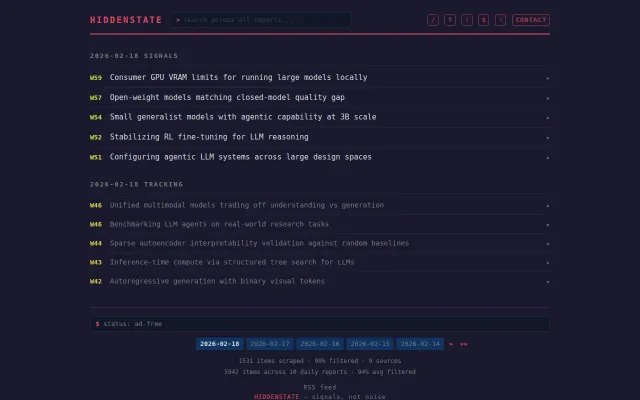
Clustering by the specific technical constraint being attacked — not by topic — and scoring each signal on convergence, implementation evidence, engagement and significance is a neat, high-signal trick for surfacing research trends. It smartly dedupes org noise and ingests many sources, though using Claude as a clustering black box means the scoring pipeline could use clearer auditability or export hooks for skeptical researchers.
AI news filter for your feeds; 10+ similar tools exist (Feedly, Nuzzel, Curated).
Turns noisy YouTube comments and Reddit threads into a tidy JSON: a 1–10 normalized score, plain-text summary, pros/cons, theme-level sentiment, and backlinks for provenance. Using an LLM as the extractor is clever — it sidesteps brittle selector-based scrapers — but it also raises obvious questions about cost, reliability, and how it handles sarcasm or sparse data that I'd want to see addressed.
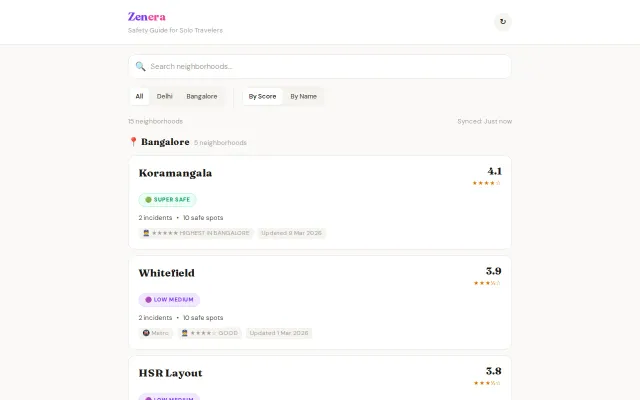
Neighborhood safety scores from 1000+ traveler reports, but only covers 4 Indian cities.