AI/ML●●Solid
Claude skill that evaluates B2B vendors by talking to their AI agents
AI agents interrogating other AI agents is a genuinely novel vendor evaluation approach.
Big BrainNiche Gem
ogotlieb
4562mo ago
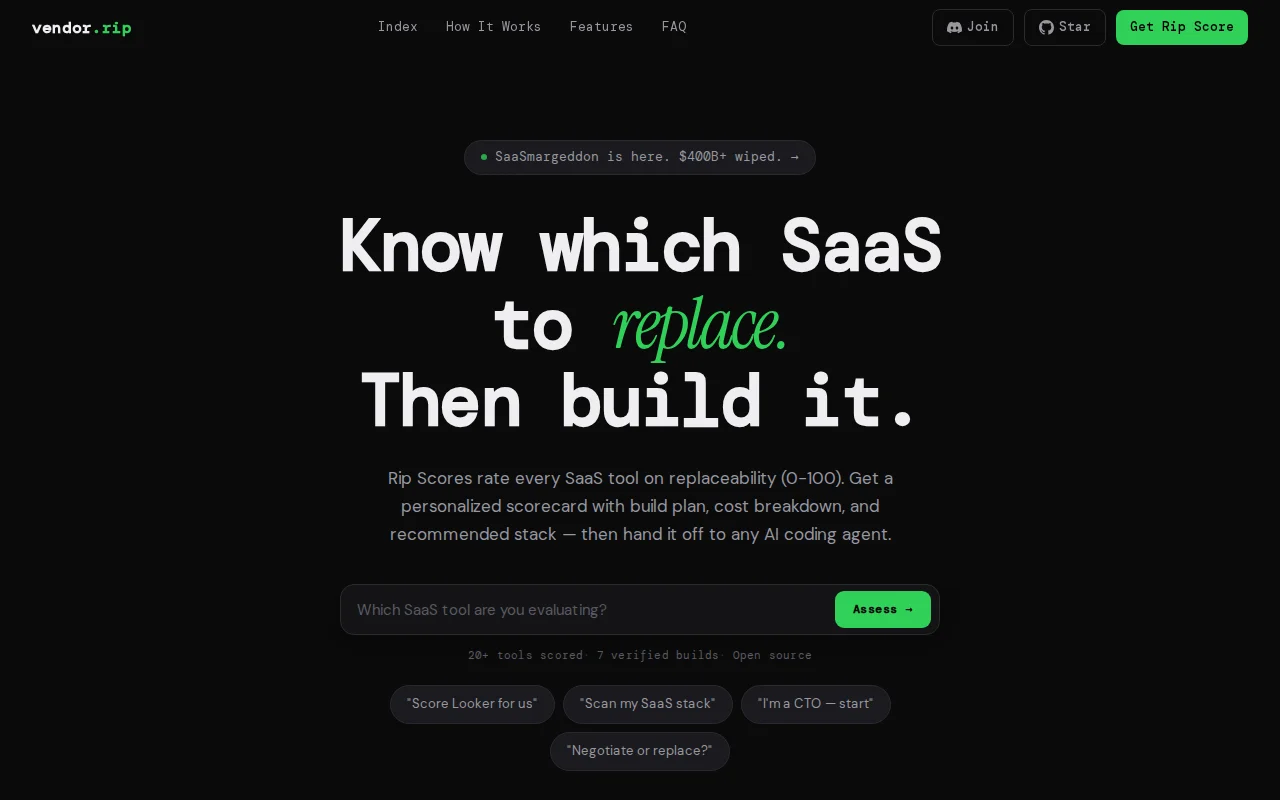
Rip Scores + AI handoff turn SaaS replacements from nebulous into build playbooks.
CTOs and engineering teams evaluating open-source alternatives to expensive tools
Y Combinator startup playbooks · AWS Migration Accelerator Program
AI agents interrogating other AI agents is a genuinely novel vendor evaluation approach.
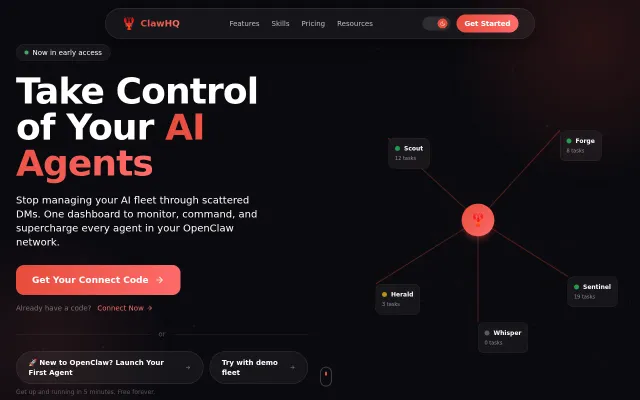
Real-time fleet view with heartbeat monitoring, drag-and-drop task kanban, and a unified agent chat paired to a one-click skill store and 80/20 creator split — that combo is useful and not something you see everywhere. Practical execution looks solid from the UI, but the product’s reach depends on OpenClaw adoption and how comfortable folks are exposing gateway URLs and installing third-party skills.
Behavioral safety testing reveals 45 regressions static analysis misses—guardrails provided.
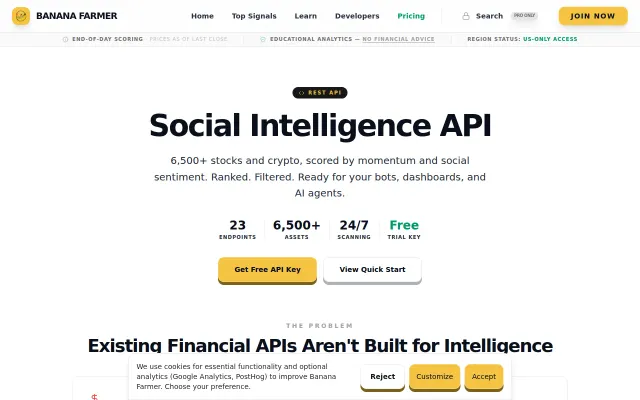
You get momentum scores, RSI, EMA alignment, coil-breakout detection and concise bull/bear briefs out of the box — plus an OpenClaw skill so an LLM agent can answer “how's $NVDA looking?” immediately. The author ships 900+ days of backtested signals and open, dependency-free Python scripts which is refreshingly transparent, but the headline win-rate/return claims need independent audit (survivorship and lookahead bias are the obvious caveats) and the product looks focused on US/end-of-day use-cases.
Test suite for LLM agent skills; fills a real gap in agent eval tooling.
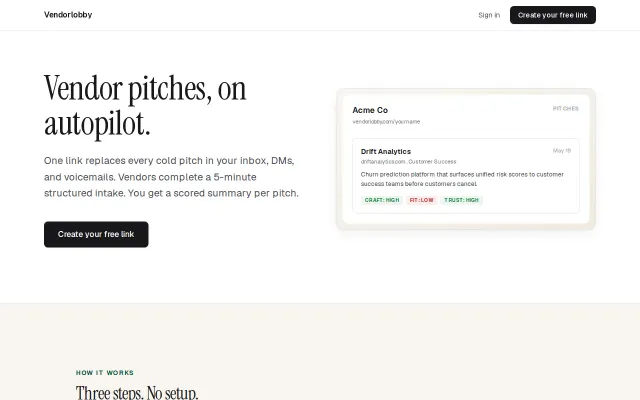
Replaces cold vendor pitches with scored intake summaries in 30 seconds.