Developer Tools●Mid
Why Two Identical PDFs Have Different SHA-256 Hashes (How We Fixed It)
Good explainer on PDF metadata, but this is a known issue with standard library fixes.
Niche Gem
napzoom
141mo ago
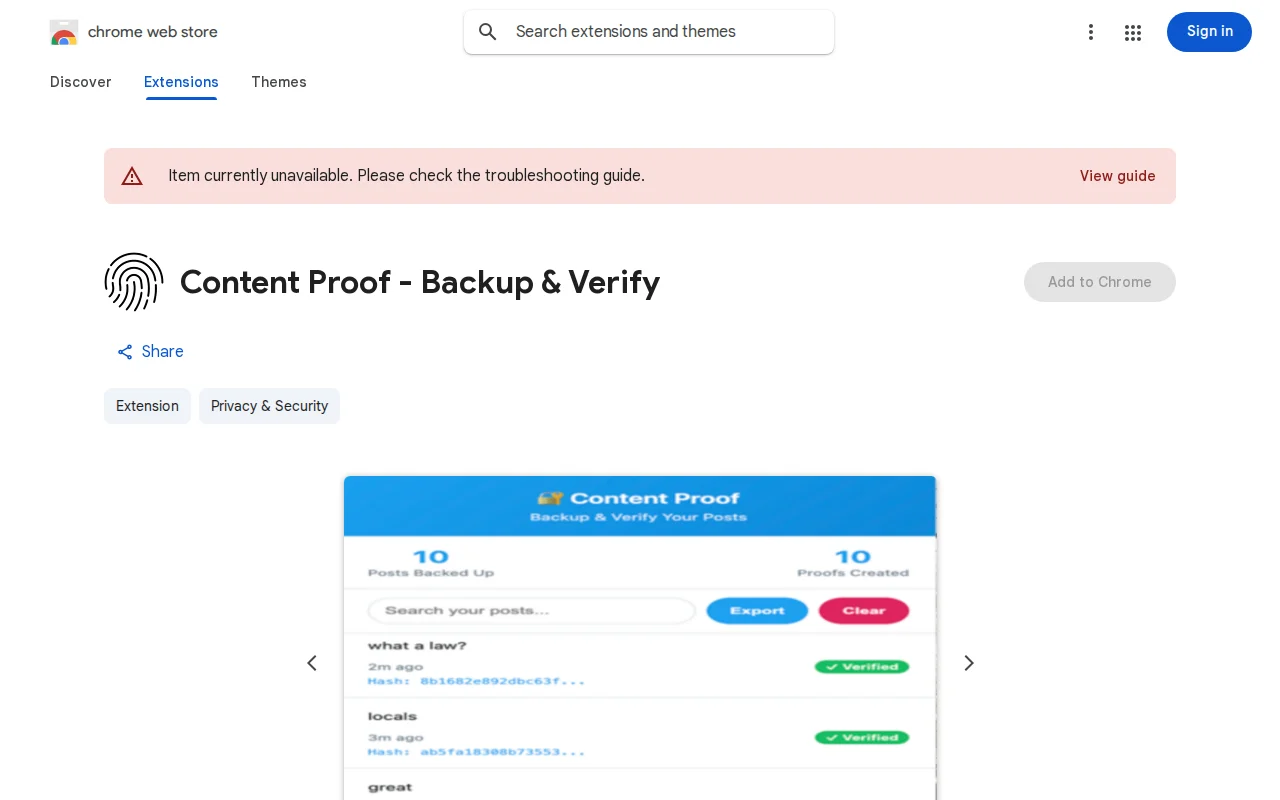
SHA-256 tweet verification for skeptics; solves screenshot-faking with deterministic hashing.
Journalists, content creators, researchers protecting tweet integrity
Wayback Machine (URL archival) · Perplexity's tweet snapshots
The goal is to preserve what a tweet actually said at a specific moment, even if it’s later edited, deleted, or disputed. Screenshots are easy to fake; deterministic data + hashing is harder to argue with.
How it works
• Extracts text, author, URL, timestamp, and available metadata • Normalizes the data into a deterministic JSON structure • Computes a SHA‑256 hash • Stores everything locally • No external requests, no backend, no analytics
Why I built it
I kept seeing important tweets disappear during investigations. I wanted a lightweight, local‑only way to preserve content with enough structure that someone else could independently verify it later.
Looking for feedback on:
• Whether SHA‑256 is sufficient for long‑term verification • Better ways to structure the proof object for interoperability • Any privacy pitfalls I might be missing • Other use cases where this approach would be useful
Happy to answer questions. The extension is intentionally minimal — I’m trying to understand whether this approach is useful beyond my own workflow.
Good explainer on PDF metadata, but this is a known issue with standard library fixes.
Hash chaining before write beats S3 Object Lock for pre-write tampering protection.
Hash-verified doc citations enforce truth—genuinely solves AI agent hallucination on stale docs.
Cryptographic proof bundles for AI agent browser actions—screenshots can be faked, hash chains can't.
SHA-256 hash chains for AI audit trails—solves EU AI Act compliance elegantly.
SHA-256 hashing raw API responses lets auditors verify evidence without trusting the tool.