AI/ML●Mid
Skim any YouTube video. be happy
Another YouTube summarizer when Eightify, Glasp, and ChatGPT plugins already dominate this space.
Ship It
betterhealth12
2114d ago
Summarizes long YouTube videos by topic—Glasp and similar extensions exist, but UX is thoughtfully tuned.
YouTube content consumers wanting to skim long videos; students, researchers, podcast listeners
Glasp · Elytra · TubeBuddy
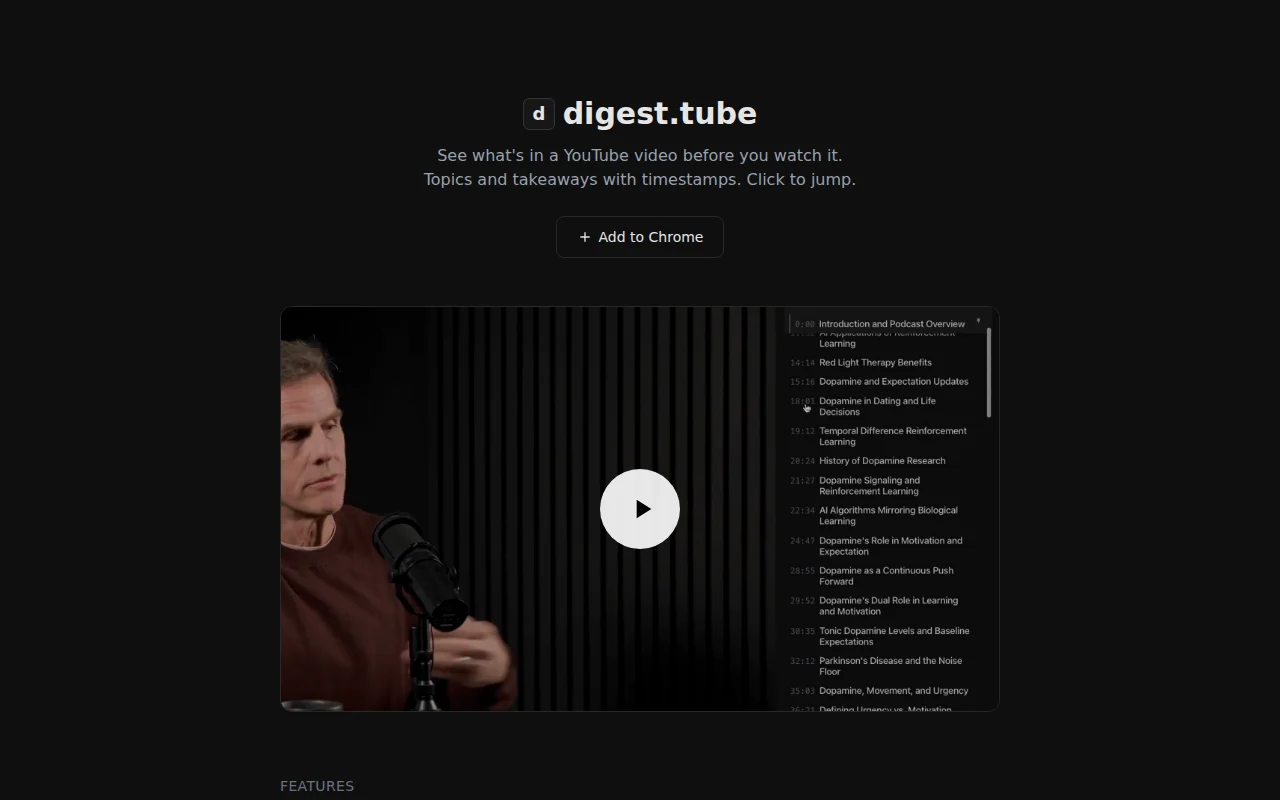
I'd like to share yet another timestamped summary tool for youtube. I tried several existing extensions but couldn't find the UX that I wanted, so I built my own.
it's a chrome extension that reads the transcript and maps out topics and key takeaways with timestamps. my usual flow is skimming the topics, hovering on the ones that sound interesting to see the takeaways, and if those look good too, clicking to jump straight there.
- if a video has already been processed, anyone can view it for free, no signup needed either
- supports videos up to ~10 hours (tested on this 8.5-hour podcast: https://www.youtube.com/watch?v=Kbk9BiPhm7o)
- the extension only activates on youtube.com. no background tracking, no browsing data
demo (30s): https://www.youtube.com/watch?v=I2K94zZfD9E
chrome web store: https://chromewebstore.google.com/detail/digesttube/idogajoe...
some implementation notes for the technically curious:
I use client-side transcript fetch since youtube throttles bots fetching transcripts. this means my api accepts user-submitted transcript text. to prevent abuse, I cache digests by transcript hash. another user only gets the cached result if their own client-fetched transcript produces the same hash.
the transcript gets split into slightly overlapping chunks with some pre/post context window. each chunk goes to the LLM in parallel, so processing scales well even for very long videos.
one challenge I'm still iterating on: topics that land right at a chunk boundary, starting just before one chunk ends and finishing just after the next begins. this sometimes leads to duplicate or fragmented topics across adjacent chunks. the overlap window helps but doesn't fully solve it. curious if anyone has tackled similar chunking problems and what approaches worked.
Another YouTube summarizer when Eightify, Glasp, and ChatGPT plugins already dominate this space.
YouTube-to-newsletter AI converter when Substack, Ghost, and Beehiiv already dominate.
Video demo of a personal workflow, not a tool others can actually use.
Another TTS wrapper competing with Speechify and NaturalReader.
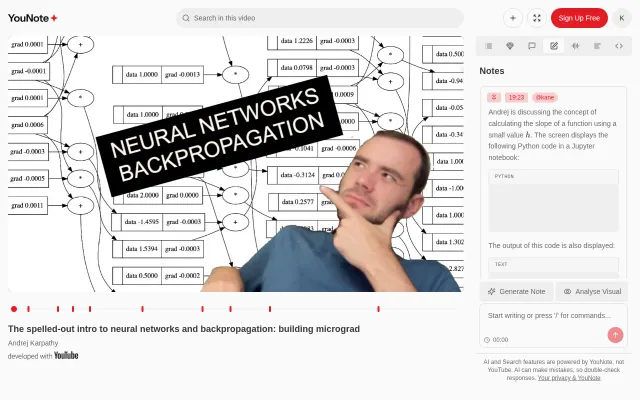
Runs Karpathy's Micrograd code directly in the browser without setup.
Yet another AI newsletter wrapper in a crowded space.

![Practicing foreign language generating conversation on topic [video]](/screenshots/48472833_thumb.webp)