AI/ML●●●Banger
Detecting LLM hallucinations in <1ms using hidden states (RTX3050, 4GB)
Detects hallucinations via hidden state geometry in under 1ms with no training required.
WizardryBig BrainDark Horse
yubainu
113mo ago
Real-time LLM hallucination guardrail — NLI + RAG fact-checking with token-level streaming halt. Drop-in for any LLM backend.
Token-level streaming halt stops hallucinations mid-sentence before user sees them—genuinely novel safety layer.
AI engineers building production agents, especially in regulated industries
Guardrails.ai · LLMGuard
After watching too many agents confidently lie in production, I built Director-AI.
It sits between your LLM and the user, scoring every generated token with: • 0.6× DeBERTa-v3 NLI (contradiction detection) • 0.4× RAG against your own ChromaDB knowledge base
If coherence < threshold → Rust kernel halts the stream before the token is sent.
Key technical bits: • Works with any OpenAI-compatible endpoint (Ollama, vLLM, llama.cpp, Groq, OpenAI, Claude…) • StreamingKernel + windowed scoring • GroundTruthStore.add() for easy fact ingestion • Dual licensing: AGPL open + commercial (closed-source/SaaS OK)
Honest AggreFact numbers inside (66.2% balanced acc with streaming enabled). Not claiming SOTA on static NLI — the value is in the live gating + custom KB system.
Repo + full examples: https://github.com/anulum/director-ai
Would love feedback on the scoring weights, halt logic, or kernel design. What hallucination problems are you solving today?
Detects hallucinations via hidden state geometry in under 1ms with no training required.
Multi-agent fact-checking loop, but RAG hallucination fixes are table stakes now.
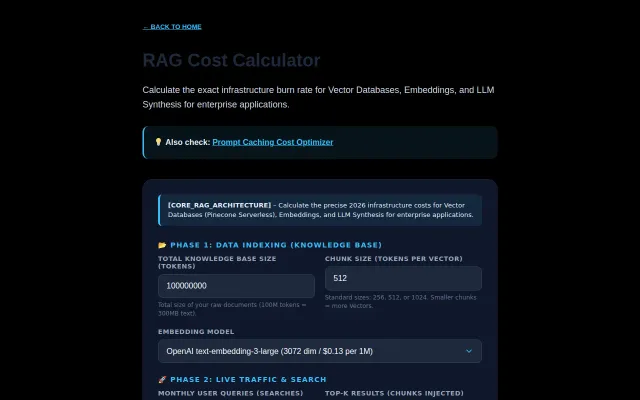
Breaks down hidden RAG costs like vector storage overhead and HNSW indexing fees.
Detects hallucinations via latent space geometry instead of text analysis, but 54% detection rate is incomplete.
Parallel translation comparison beats single-source RAG for theological accuracy.
Crowded AI marketplace model overshadows the genuinely clever AST-based code editing technique.