AI/ML●●Solid
Voice gender classifier for European voice AI (1MB, ONNX, 4ms)
Enables grammatical gender inflection in EU voice agents with 4ms CPU inference.
Niche GemSlick
biduskamil
521mo ago
A high-performance name classifier that infers probabilistic attributes about a person from their name alone.
Character-level morphology + ensemble ensemble beats cascades; handles multilingual names honestly.
Data scientists, HR analytics, demographic research, NLP practitioners
genderize.io · Gender R package · Predicting gender from names (scikit-learn examples)
It's useful for estimating demographics in large datasets from limited information, i.e. just a name.
It's also fairly good at separating given name and family names across a wide variety of languages and contexts.
Contains a standalone binary, embeddable shared lib, and a python wrapper.
Examples
CLI:
user@box » ./build/name-classifier -j -c "Carlos Eduardo Fernando Salazar Montemayor" | jq .
{ "input": "Carlos Eduardo Fernando Salazar Montemayor", "script": "latin", "components": [ { "token": "Carlos", "role": "given", "index": 0, "surname_score": 0.009 }, { "token": "Eduardo", "role": "given", "index": 1, "surname_score": 0.001 }, { "token": "Fernando", "role": "given", "index": 2, "surname_score": 0.01 }, { "token": "Salazar", "role": "family", "index": 3, "surname_score": 0.998 }, { "token": "Montemayor", "role": "family", "index": 4, "surname_score": 0.975 } ], "attributes": { "gender": { "male": 0.9938, "female": 0.0062, "neutral": 0 }, "origin": { "english": 0, "french": 0, "germanic": 0, "nordic": 0, "iberian": 1, "italian": 0, "eastern_european": 0, "arabic": 0, "east_asian": 0, "south_asian": 0, "southeast_asian": 0 } }, "calibrated": true, "model_version": "embedded", "provenance": { "gender": { "lexicon": 0.598, "ngram": 0.302, "neural": 0.101 }, "origin": { "lexicon": 0, "ngram": 0, "neural": 0 } } }
Python:
from name_classifier import NameClassifier
nc = NameClassifier(args.model_dir)
nc.classify("Kateryna Olha Mykhailivna Shevchenko")
Enables grammatical gender inflection in EU voice agents with 4ms CPU inference.
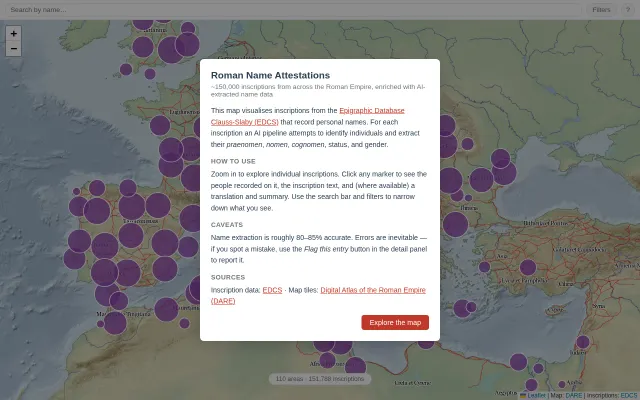
AI-extracted names from 150k Roman inscriptions mapped across the empire.
Yet another CSS framework — attribute syntax isn't novel enough to escape Tailwind's shadow.
Clean UI for Chinese name generation, but ChatGPT does this natively without a wrapper.
Classifies AI query results as fact, inference, or unknown without using embeddings.
Exhaustive LLM name scoring is thorough, but baby-naming tools and SSA data already exist.