Education●●●Banger
How-to-Train-Your-GPT
Build a LLaMA-style model from scratch with zero ML prerequisites or math.
CozyBig Brain
RaiyanYahya
101mo ago
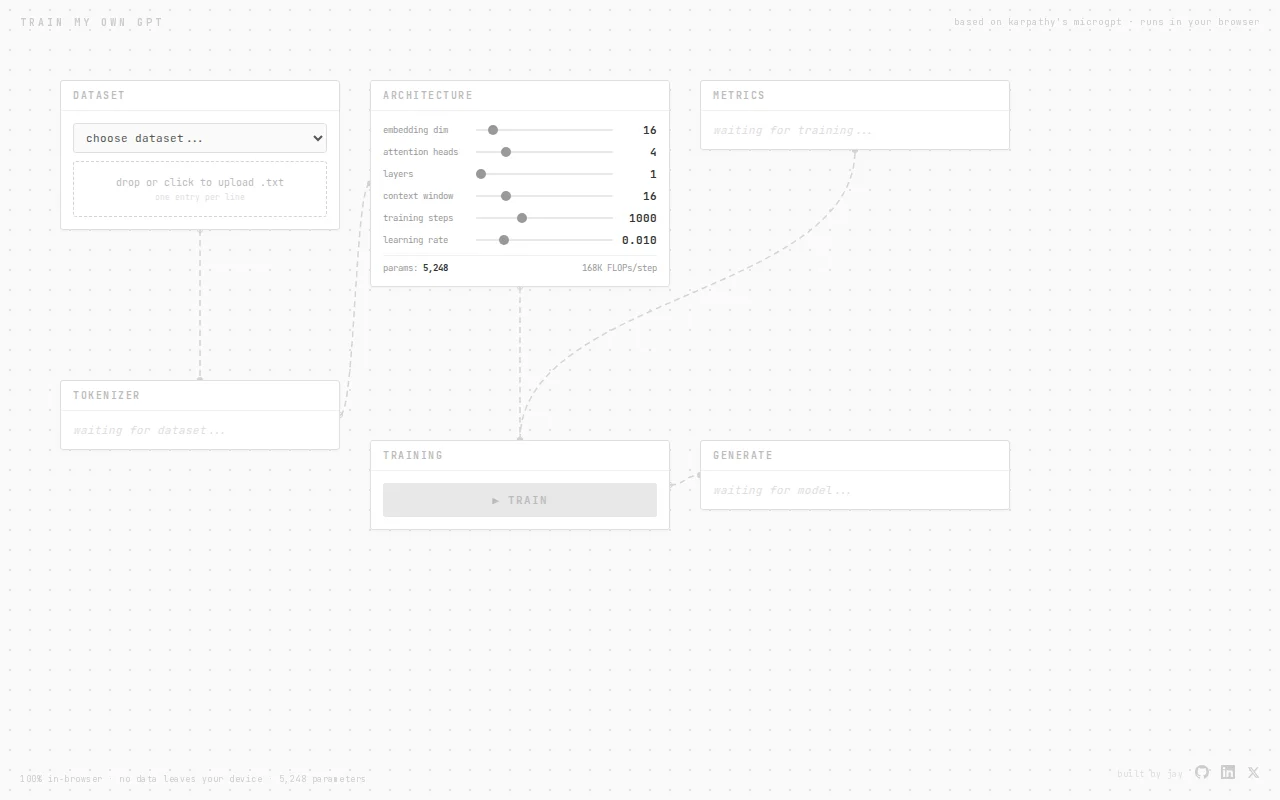
Karpathy's microGPT in the browser with live loss curves, but pedagogical only—no production value.
ML learners, educators, developers curious about transformer internals
fast.ai · TensorFlow.js examples · Andrej Karpathy's makemore
Build a LLaMA-style model from scratch with zero ML prerequisites or math.
Explains attention mechanisms to five-year-olds while building LLaMA 3 from scratch.
Karpathy's microgpt in C99, proves tiny coordinated models beat single large models on logic.
Type a name and you can literally watch characters turn into IDs, 16‑dim embeddings get added with positional encodings, and causal attention matrices animate per head — all matched numerically to Karpathy's 244‑line microGPT. The implementation is pure TypeScript (no ML libs) and includes a helpful scrollable sidebar with the reference math, which makes this an excellent, low‑friction learning tool — more pedagogical deep dive than research innovation.
The author minified Karpathy’s MicroGPT, ported it to 39 lines of JS (including a tiny autograd, MHA, AdamW and training loop) and shoehorned the whole gzipped HTML into a version-40 QR code that the browser decompresses and runs. It's clearly a stunt — the model is toy-scale (≈4k params, 8-token context) — but the compression trick, browser-native DecompressionStream use, and runnable-in-QR delivery are a delightful technical flex.
Pure C99 GPT with SIMD beats Python 4,600x; drop two files into any project.