Developer Tools●●Solid
Record manual QA flows, get E2E test code that fits your repo
Records flows and auto-fixes failing tests until green.
SlickBold Bet
mihau
1922mo ago
Claude drafts tests locally; Decipher executes and fixes failures in cloud—smart division of labor.
QA engineers, development teams using Claude Code and Playwright
Playwright Inspector · GitHub Copilot test generation · Synapse QA
Today we’re launching our Claude Code integration.
We built this because as teams ship more code, especially with coding agents, they need more regression coverage. Claude can already generate a decent Playwright file from a repo and prompt. That solves first-draft generation. It does not solve repeatability.
A generated test is still a static guess. The real problems start when it meets the live app: the browser is logged out, a modal appears, a feature flag changes the path, a selector is stale, or the app changed in a way that requires updating the test without changing what it is supposed to verify.
That is the gap between “Claude wrote a script” and “we have durable E2E coverage.”
Our system splits that loop in two. Claude handles local planning: it reads the request, inspects the repo, infers the flow, and drafts the initial step plan. Decipher handles runtime: agents in our infrastructure run the steps in a live browser, observe what happened after each step, classify failures, and use the product knowledge captured during planning to repair the failing segment.
Once the test is on Decipher, our agents continue maintaining it against the test’s original intent. As the UI or flow changes, they update the test mechanics without silently changing what the test is supposed to verify.
We chose Skills + CLI instead of MCP because this is not a single tool call. It is a stateful loop: gather context, compile steps, start a remote run, inspect runtime state, patch failures, and resume. The CLI handles auth and transport. Skills keep Claude on that path and preserve a clean boundary between local context and remote execution.
In practice, Claude builds an initial plan and sends it through the CLI to our backend. A remote worker runs it against the live app in a cloud browser. The remote agent turns Claude’s steps into real actions on the product, figuring out the right element to click and modifying steps as needed. After each step, or on failure, the Decipher agent sends structured state back to Claude: what step ran, what the agent did, what state the page is in, what kind of failure happened, and the artifacts needed to repair it. Claude can then chime in and make changes.
Feel free to give it a try. We'd greatly appreciate any feedback you might have.
Records flows and auto-fixes failing tests until green.
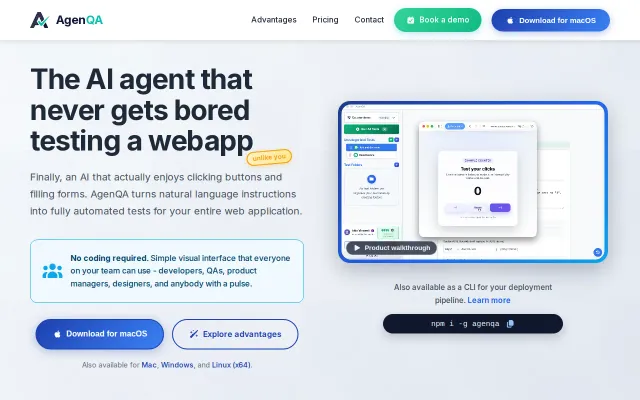
Natural language E2E tests sound good until you need debugging or maintenance.
Natural-language -> E2E tests plus a visual desktop app, cloud sync and an npm-installable CLI is a pragmatic combo that will appeal to teams tired of brittle scripts. Usability-focused reporting and a recorder-ish desktop experience are the clearest differentiators here; what I want to see next is concrete evidence about cross-browser reliability and how the AI handles flakiness and changing selectors.
AI E2E testing when Playwright, Cypress, and Testim already dominate.
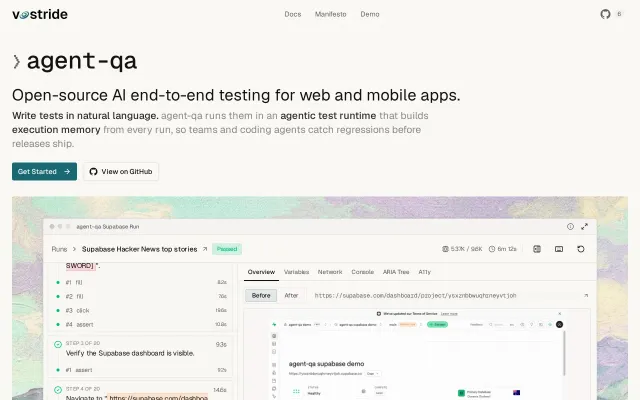
Agentic test runtime builds execution memory to heal flaky tests automatically.
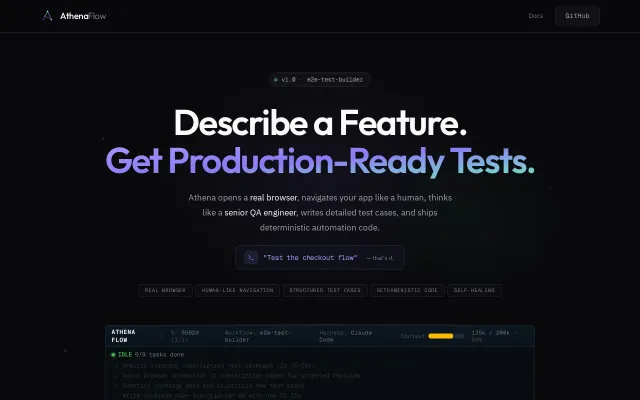
E2E test builder using Claude Code with semantic browser snapshots, but execution depends on Claude's availability.