AI/ML●●Solid
I built proxy that keeps RAG working while hiding PII
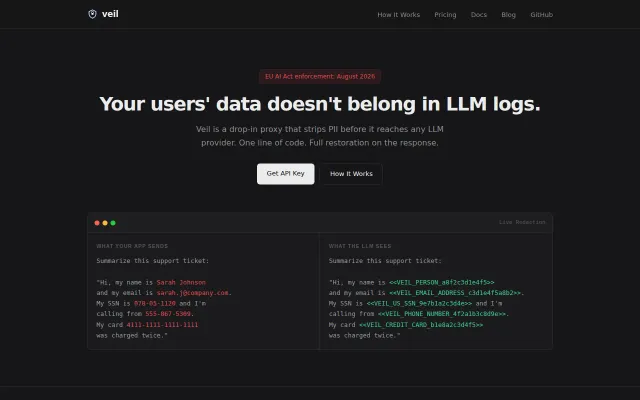
Consistent pseudonymization beats redaction when RAG embeddings must survive.
Big BrainSolve My Problem
rohansx
403mo ago
Multi-model LLM router with semantic cache, but caching+fallback already exist (Anthropic, LangSmith, Unify).
AI app developers and teams managing multi-model inference pipelines at scale
Anthropic Models API · LangSmith · Unify.ai
Consistent pseudonymization beats redaction when RAG embeddings must survive.
Semantic caching with dependency invalidation beats standard Redis wrappers for agent costs.
Local semantic caching cuts LLM costs without changing your code.
Stops zero-width Unicode bypasses that break standard PII filters before LLM calls.
Yet another PII redaction proxy when Lakera and Portkey already dominate this space.
Semantic caching for LLM APIs exists (Anthropic prompt caching, Langchain, Miniplex, vLLM); gateway routing is table stakes.