AI/ML●●Solid
ÆTHERYA Core – deterministic action-governance kernel for LLM agents
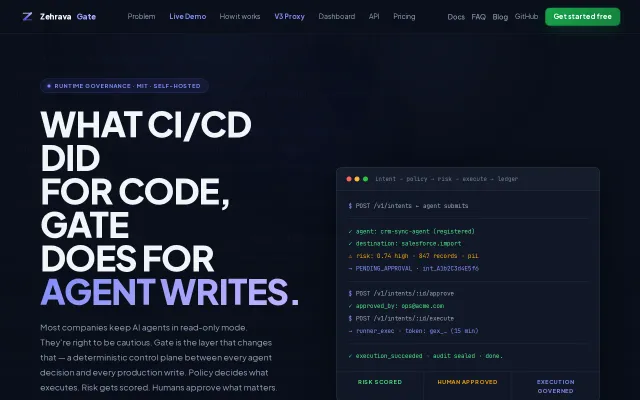
Fail-closed policy layer blocks LLM tool calls before execution, no LLM in decision path.
Big BrainNiche Gem
RobertMihai
103mo ago
Deterministic decision engine with receipts for agents
Auditable agent decisions via DAG receipts—unlike prompt-dependent LLMs, this proves reasoning.
AI engineers, compliance teams, high-stakes decision systems (drug interactions, sanctions screening, threat detection)
Langchain agents with memory · Prolog/logic programming engines · Supabase for structured queries
Every query returns a DAG receipt showing exactly how the result was derived (nodes traversed, filters/constraints applied, outputs). The goal is to make agent decisions auditable and reproducible instead of prompt-dependent.
I built this because LLMs are strong at orchestration and general reasoning, but high-stakes decision logic often needs deterministic execution and explicit proof trails. Cruxible receipts are meant to be audited, replayed, and challenged.
There’s also a feedback loop: users can approve/correct/reject edges and update confidence/evidence, so domain knowledge and decision trails compound across sessions.
Demos included: - Drug interactions (DDinter + CYP450) - OFAC sanctions screening (ownership chains) - MITRE ATT&CK threat modeling
Known limitations: - Candidate edge generation is still basic (property matching, shared-neighbor analysis, AI suggestions) - No application/action layer yet (e.g., transaction blocking, clinical alerts) - --limit queries currently persist full receipts instead of pruning to returned rows (fix planned)
Repo: https://github.com/cruxible-ai/cruxible-core
Thank you for reading! Feedback I’d value most: 1. What limitation makes this less useful for your domain? 2. Any setup/usability issues you hit? 3. Structural criticism of the approach
Fail-closed policy layer blocks LLM tool calls before execution, no LLM in decision path.
Agent governance is a real need, but closed-source binaries prevent code evaluation.
Offline artifact verification with signed governance, but what threat model does this solve?
CI/CD for agent writes with deterministic YAML policies, no LLM at eval time.
Deterministic capture + replay for LLM agents is a practical, under-served problem and this repo actually ships a 'golden run' zip with cold‑run verification hashes — that’s the kind of evidence chain auditors want. The focus on portable evidence bundles and stress verification suggests useful forensics and load testing of agent logic, but the release page looks early-stage; I'd like to see integrations (tooling for popular agent frameworks), richer docs, and example pipelines before I'd evangelize it.
Five queries vector stores can't answer: why(), tensions(), blocked(), whatIf(), alternatives().