AI/ML●Mid
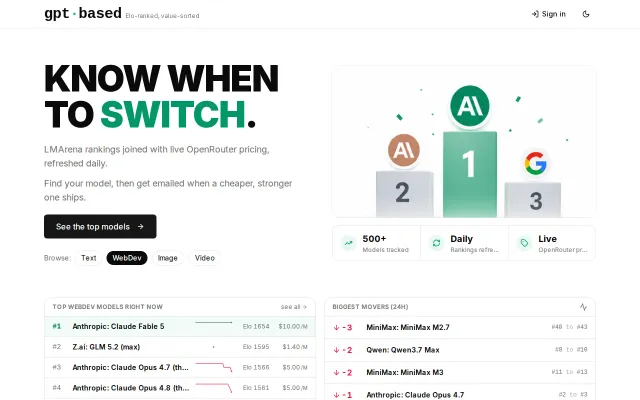
Gptbased – LLM leaderboard that emails you when to switch
Pareto frontier optimization finds cheaper, stronger models when they ship.
Solve My Problem
gptbased
104d ago
🪂 Latency-aware model cascade for agentic LLM workflows. Auto-switches to a faster model when yours is slow.
TTFT-aware model fallback—avoids timeouts by hedging between Opus, Sonnet, Haiku automatically.
Developers building agentic LLM workflows, AI engineers managing inference latency.
LiteLLM · Anthropic batch API · request hedging patterns in Envoy/Thrift
Pareto frontier optimization finds cheaper, stronger models when they ship.
Zero-code LLM firewall; heuristics under 1ms, optional Groq semantic layer.
Self-hosted OpenRouter Fusion alternative with tunable judge strategies.
VERONICA puts an enforcement shim between your agent and the model so you can halt costly spirals before a request hits the provider — it natively exposes hard budget enforcement, circuit breakers, retry containment and degradation levels. The README + runnable runaway-loop demo make the failure mode concrete and the API (BudgetEnforcer, RuntimeContext, BudgetExceeded) is small and practical. I'd like to see richer observability/adapter docs for common agent frameworks, but as an enforcement-first primitive this is a clever, useful tool.
Local semantic caching cuts LLM costs without changing your code.
Proxy pseudonymizes sensitive data so LLMs don't hallucinate like they do with regex.