Developer Tools●●●Banger
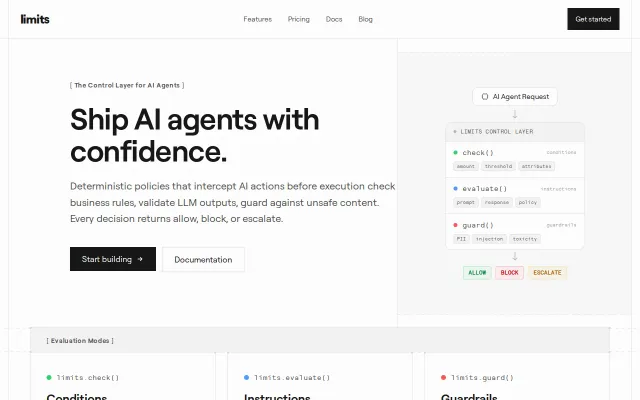
Limits – Control layer for AI agents that take real actions
Wire-protocol interception means zero code changes; solves LLM control drift in production.
Solve My ProblemSlick
thesvp
923mo ago
🔪 Open-source safety firewall for AI agents. Intercepts tool calls before they execute, enforces YAML policies, and kills dangerous operations in real-time. Works with OpenAI, Anthropic, LangChain, and MCP. She doesn't guard. She kills.
Deterministic <1ms policy kill switch for AI agent tool calls, zero ML.
Enterprises deploying AI agents, security teams enforcing tool-use boundaries
SandboxAI · Courtyard · Anthropic token control
Wire-protocol interception means zero code changes; solves LLM control drift in production.
Prevents `rm -rf ~` from your hallucinating agent in two commands, works with any CLI tool.
OPA policies plus signed tokens beat prompt engineering for agent safety.
Blocks terraform destroy and git push before agents execute destructive commands.
Mathematically verified policies enforced outside the model—formal proof replaces prompt engineering.
Addresses real risk: AI agents currently run unrestricted—SentinelGate proxies all actions.