AI/ML●●●Banger
Dewey – Ingest docs, search semantically, get cited AI answers
Structure-aware chunking beats flat embeddings for accurate multi-hop research and citations.
Big BrainSlickSolve My Problem
lambdabaa
302mo ago
Stop indexing noise. Turn messy websites and PDFs into clean, structured data for RAG pipelines with semantic importance scoring and token optimization.
Noise-filtered PDF/web extraction for RAG, but already solved by Jina, Firecrawl.
RAG builders, LLM engineers indexing documents, LangChain/LlamaIndex users
Jina Reader · Firecrawl · AWS Textract
Structure-aware chunking beats flat embeddings for accurate multi-hop research and citations.
Waitlist for RAG platform launching in 2 months with no demo.
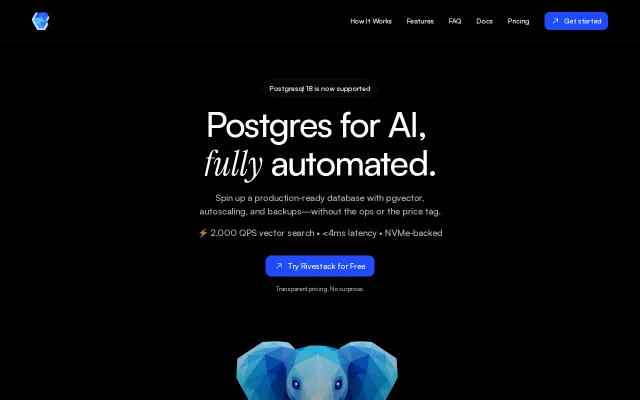
It spins up dedicated Postgres instances with pgvector pre-installed, uses Patroni for HA and pgBackRest for snapshots, and publishes concrete vector benchmarks (2k QPS @ <4ms for 10k vectors; 252 QPS at 1M). The stack choices (Hetzner NVMe, read replicas, HNSW) feel pragmatic for teams who don't want serverless/shared trade-offs, though I'd want clearer SLA/multi-region details and independent benchmarks at larger scales before moving critical workloads.
Cache-aware LLM eval with self-hosted model support beats Ragas on flexibility.
Free SEO audit wrapper when Ahrefs and SEMrush already dominate this space.
Railway 404 error page means the project isn't actually accessible yet.