Developer Tools●●Solid
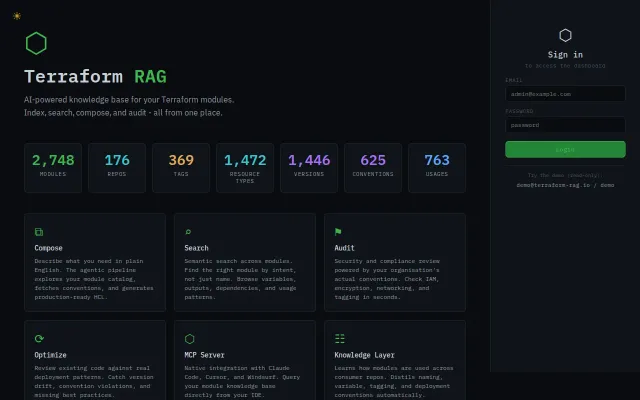
Terraform RAG - index modules, distill conventions, compose via MCP
MCP integration with Cursor and Claude Code sets this apart from generic RAG tools.
Niche GemSolve My Problem
kitgw
5111d ago
tiny memories
Embedded semantic search without vector DB or LLM calls—just save and git commit.
Developers building LLM apps with small private corpora (codebases, notes, docs)
LlamaIndex · Chroma · llamafile
MCP integration with Cursor and Claude Code sets this apart from generic RAG tools.
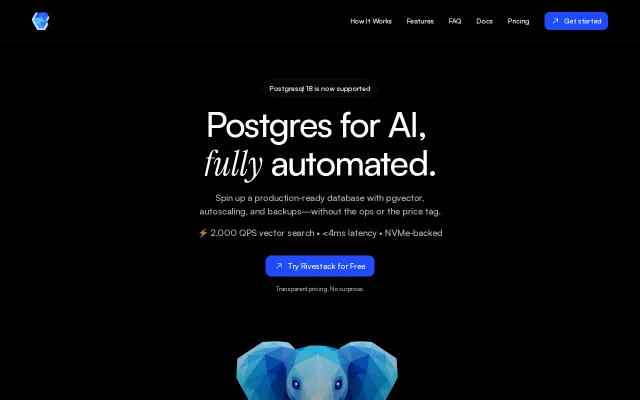
It spins up dedicated Postgres instances with pgvector pre-installed, uses Patroni for HA and pgBackRest for snapshots, and publishes concrete vector benchmarks (2k QPS @ <4ms for 10k vectors; 252 QPS at 1M). The stack choices (Hetzner NVMe, read replicas, HNSW) feel pragmatic for teams who don't want serverless/shared trade-offs, though I'd want clearer SLA/multi-region details and independent benchmarks at larger scales before moving critical workloads.
Triple-LLM failover (Gemini → Llama 3.3 via OpenRouter → Groq), local BGE‑M3 embeddings and FAISS-backed retrieval show someone thought about latency and uptime, not just model demos. The README brags about 33k pages and 'non-hallucination' claims but stops short of evaluation details or realistic ops guidance — running 70B models and local embedding stacks is impressive on paper but a heavy lift in practice.
LLM-identified discourse boundaries beat fixed-size chunking for complex queries.
Local RAG + MCP for Claude with zero external dependencies—elegant constraint execution.
RAG for Frappe when LangChain and LlamaIndex already support custom integrations.