AI/ML●●Solid
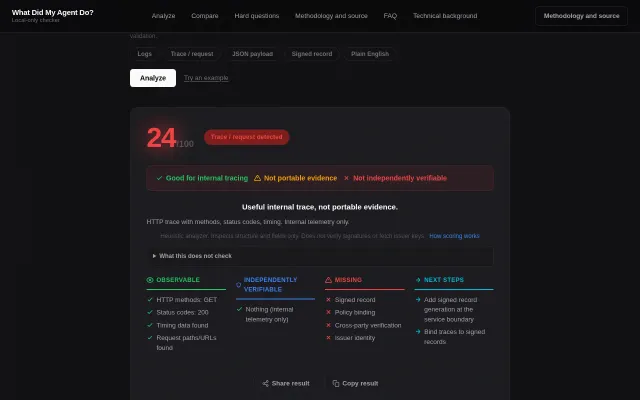
Check whether agent logs are independently verifiable
Ed25519 signature verification in browser solves agent accountability for disputes.
Big BrainZero to One
jithinraj
3015d ago
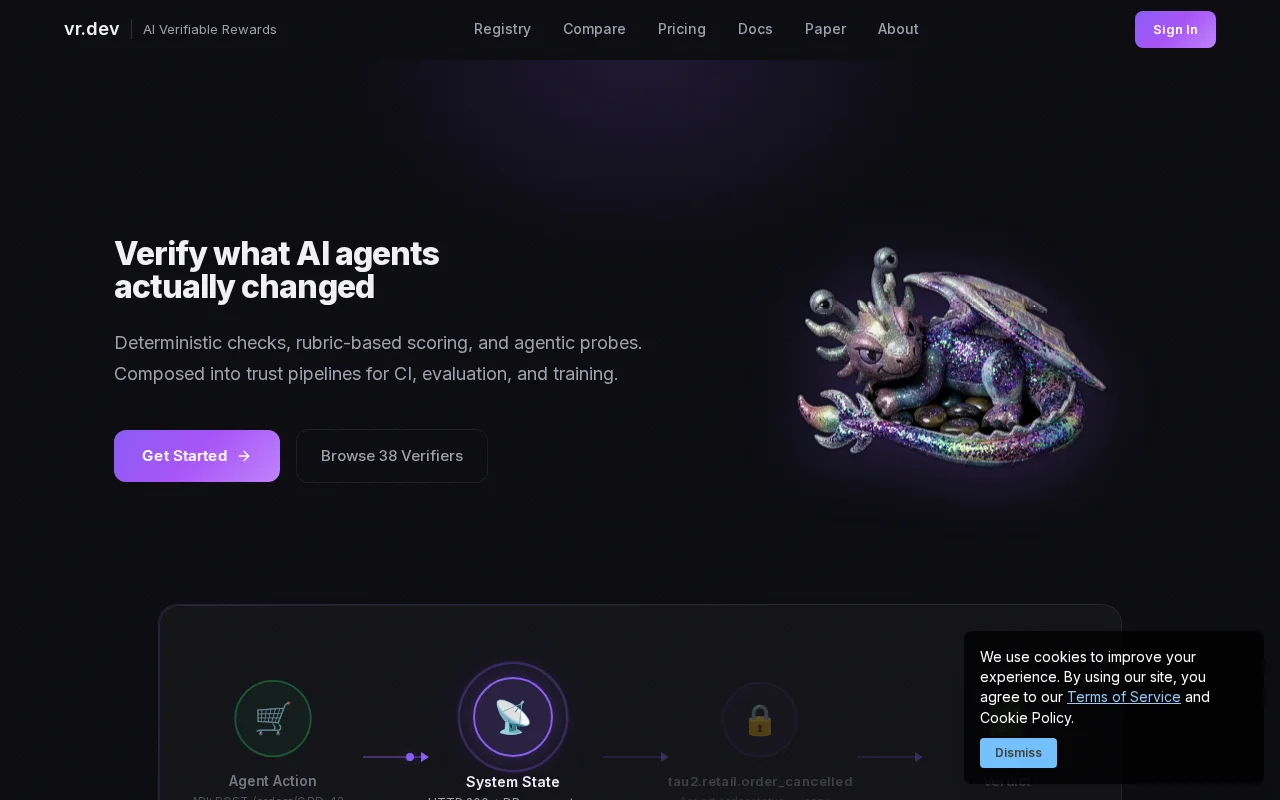
38 verifiers across 19 domains catch false successes before users do.
Teams building and training AI agents
Gate · LangSmith · Arize
Quick origin story: vr.dev started as a virtual reality project. The domain fit perfectly. The developer adoption did not. Rather than let a good domain go to waste, I pivoted to the other kind of VR: verification and rewards for AI agents.
The problem I kept running into: agents report success but system state tells a different story. The database row is still active. The IMAP sent folder is empty. The tests pass because the agent modified the tests. Real benchmarks put agent success at 12-30%, and even among reported successes a large fraction are procedurally wrong in ways that are hard to catch without actually checking state.
So I built a library of verifiers that check real system state rather than trusting agent self-reports. There are 38 of them across 19 domains right now, organized into three tiers: HARD (deterministic probes against databases, files, APIs, git), SOFT (LLM rubric scoring for things like tone or coherence that don't have a deterministic test), and AGENTIC (verifiers that actively probe the environment via headless browser, IMAP, or shell).
The design decision I'd most like feedback on is the composition model. SOFT scores are gated behind HARD checks, so if the deterministic check fails, the composed score is 0.0 regardless of what the LLM judge says. The idea is to make reward hacking structurally harder rather than just hoping the judge catches it.
MIT licensed, runs locally via pip install vrdev, no dependency on the hosted API which matters if you're using it in a training loop. Full verifier list at https://vr.dev/registry.
Curious whether the HARD/SOFT/AGENTIC taxonomy makes sense to people, whether fail_closed is the right default, and whether anyone has built something similar and run into problems I haven't hit yet.
https://vr.dev https://github.com/vrDotDev/vr-dev https://pypi.org/project/vrdev/
Ed25519 signature verification in browser solves agent accountability for disputes.
Formal verification for LLM workflows—CTL model checking, Z3 proofs, zero hallucination math.
Scores agent logs on verifiability, separating internal traces from portable evidence.
Agents verify Bitcoin math, not fiat trust—clever thesis, but infra-heavy and unproven at scale.
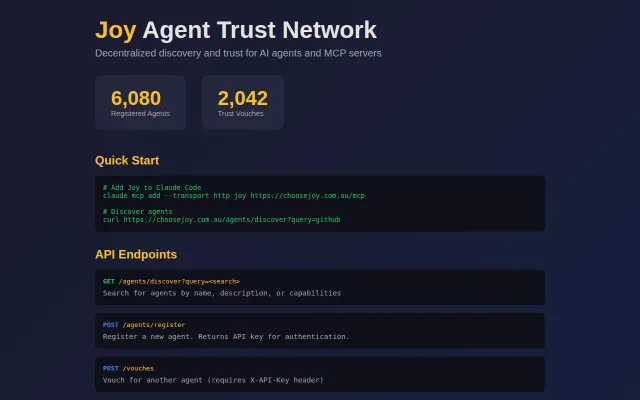
Vouch decay prevents stale trust accumulation in a crowded agent reputation space.
Delegation chains with accumulating caveats narrow authority at each agent hop.