AI/ML●●Solid
Flexorch-audit – quality scoring and PII detection for LLM pipelines
Regex-only PII detection with zero dependencies when Presidio already exists.
Solve My ProblemCozy
flexorch
203d ago
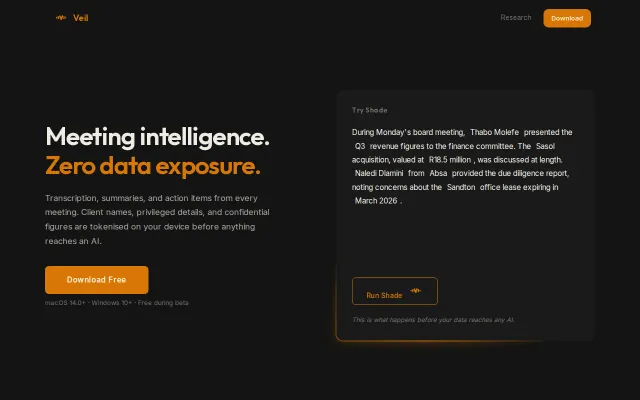
Phonetic embeddings catch ASR-mangled names across cultures before LLM sees them.
Developers building AI pipelines handling sensitive data
Microsoft Presidio · Amazon Comprehend
The problem: AI agents processing meetings, emails, support tickets are handling raw sensitive data. Names, salaries, medical details — all flowing through cloud APIs.
The solution: Detect PII on-device, replace with tokens ([PERSON_1], [AMOUNT_1]), send safe tokens to LLM, rehydrate response locally.
Interesting finding: In benchmarks (98 scenarios, 8 verticals, Claude Haiku), accuracy went UP with PII redaction — 91.5% → 93.3%. Token-structured input seems to help models parse arguments more reliably.
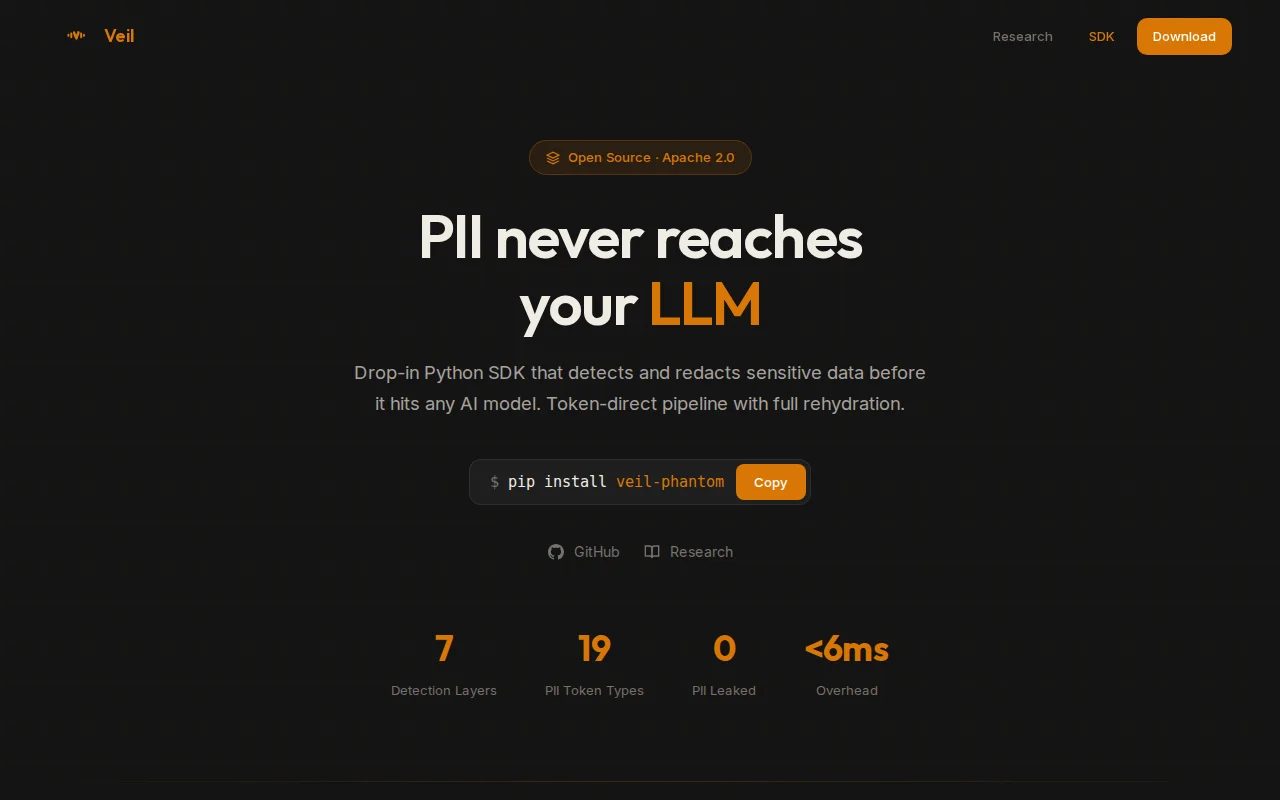
Technical details: - Shade V7: 22M param PhoneticDeBERTa (DeBERTa-v3-xsmall + Double Metaphone embeddings) - Trained on 72M words of meeting/business data - 7 detection layers (NER, gazetteers, regex, NLP, contextual) - 19 PII token types - 6ms average overhead - 97.1% F1 on meeting transcripts
The phonetic embeddings help catch ASR-mangled names across cultures — "Nkosinathi" transcribed as "Ink Casino Thea" still gets detected.
pip install veil-phantom
Docs + benchmarks: https://helloveil.com/sdk GitHub: https://github.com/helloveil/veil-phantom
Apache 2.0. Happy to answer questions about the architecture or training approach.
Regex-only PII detection with zero dependencies when Presidio already exists.
Local neural network catches leaks in 150ms with zero telemetry.
Local PII masking for ChatGPT—free and zero-server, but detection accuracy unverified.
Three-line fix for GDPR Article 44 violations when LLM prompts contain EU user data.
Custom PII model runs on-device before AI sees anything—solves real data exposure in meeting tools.
Format-preserving PII replacement lets LLMs process data without seeing real values.