AI/ML●Mid
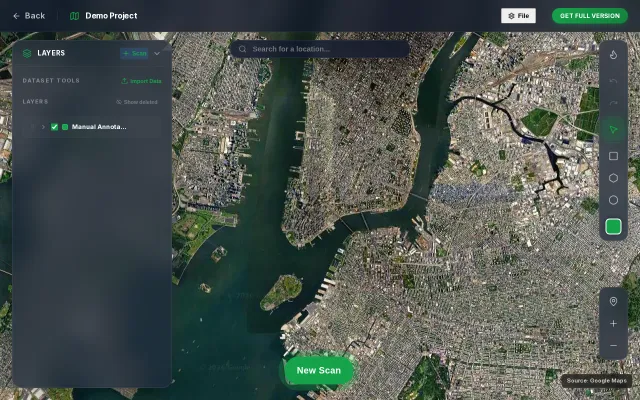
Satellite imagery object detection using text prompts
VLM-based satellite detection sounds good until you remember YOLO and specialized models handle occlusion better.
Ship ItEye Candy
eyasu6464
53233mo ago
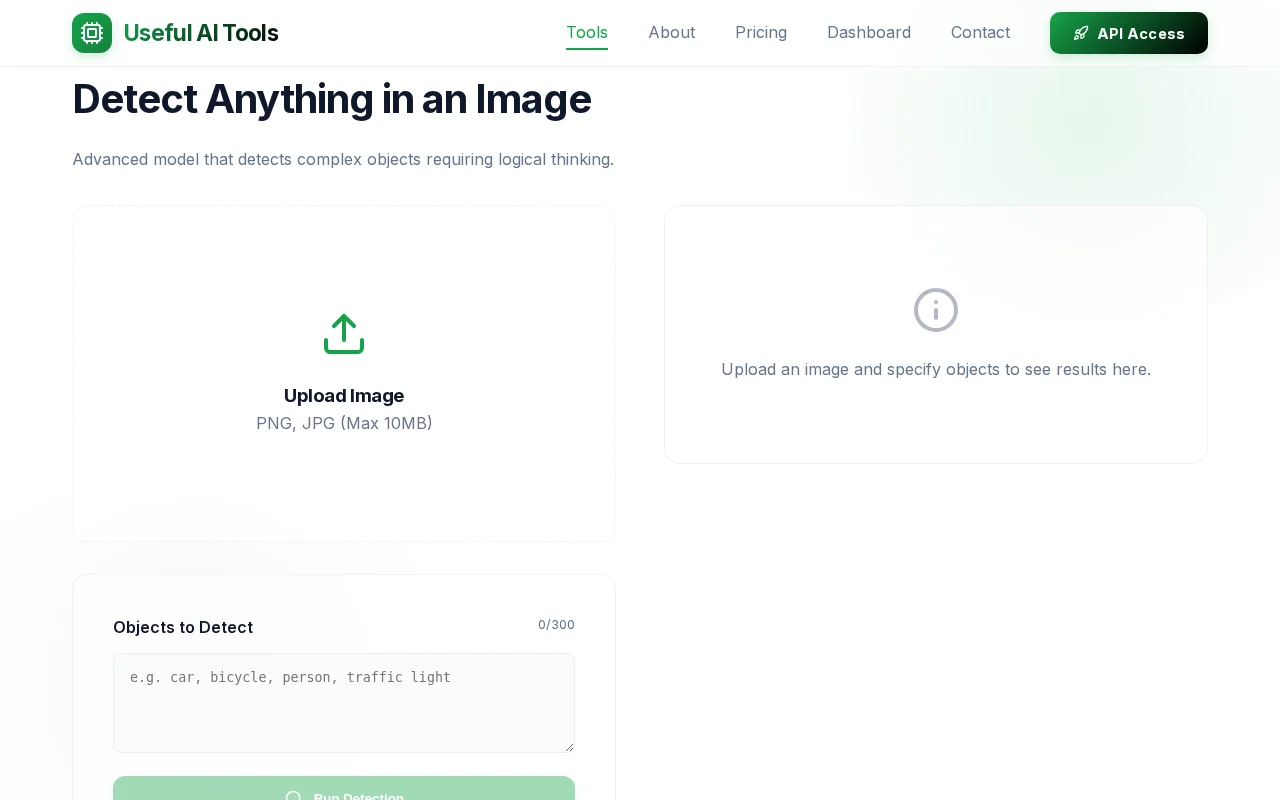
Open-vocabulary object detection exporting to YOLO format without login requirements.
Data scientists, ML engineers, QA inspectors
Roboflow · Hugging Face Spaces
Instead of training a detector for a fixed set of classes, you can type what you want to find and the system returns bounding boxes for matching objects.
Examples of prompts: "dented car bumper" "person wearing red backpack" "cat scratching couch" "broken window"
The model is open-vocabulary, so it can generalize beyond predefined categories.
I originally built this while experimenting with ways to bootstrap datasets for training YOLO models without manually labeling thousands of images. The detections can be exported as labels and used to train a traditional detector.
There is a demo where you can upload an image and try different prompts.
Curious where people think prompt-based detection is actually useful in real workflows (dataset labeling, QA inspection, etc.).
VLM-based satellite detection sounds good until you remember YOLO and specialized models handle occlusion better.
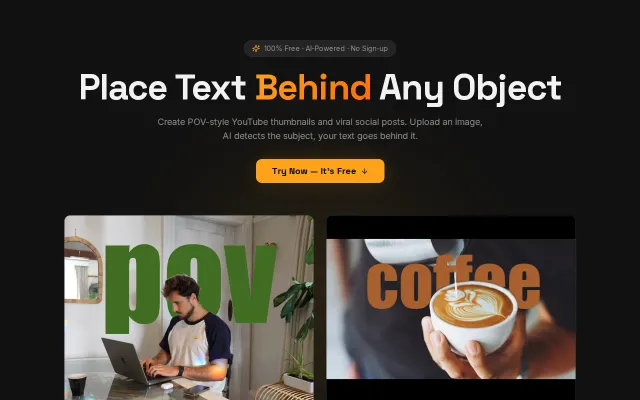
AI object detection for text placement, but Canva and Adobe Express already do this better.
Tile-based VLM inference with coordinate projection, but dense objects still need YOLO.
Broken link to a Medium article means there is no project to review.
The author documents ripping out Ultralytics and training YOLOX end-to-end on an aircraft dataset, releasing code under an MIT license so you can run and modify the whole pipeline yourself. This is the sort of no-frills, reproducible recipe that saves time if you need full control over configs, checkpoints and licensing — not novel research, but genuinely useful for people who hit the limits of packaged repos.
CV-based port detection exists, but privacy warnings kill enterprise adoption.