Infrastructure●●●Banger
Autofoundry – Run autoresearch across any cloud GPU with one command
Multi-cloud GPU orchestration in one command beats provisioning each provider separately.
Solve My ProblemSlick
shea256
113mo ago
Runs hundreds of RAG eval configs in parallel on one GPU using online aggregation.
ML Engineers building RAG pipelines
Ragas · Arize Phoenix · DeepEval
We built RapidFire AI, an open-source framework that lets you compare dozens (or hundreds) of RAG and context engineering configurations in parallel, without needing a GPU cluster.
The problem: Tuning a RAG pipeline means experimenting with chunk sizes, embedding models, retrieval strategies, reranking thresholds, prompt schemes, generator models, and more. With traditional tools, you run these sequentially, wait for each to finish on the full dataset, and then compare. That's painfully slow and wastes tokens/compute on configs you'd have killed after seeing the first 10% of results.
Our approach: RapidFire AI shards your eval dataset and schedules all configs one shard at a time, cycling through them with efficient swapping. You get running metric estimates with confidence intervals in real time, based on online aggregation from the database systems literature. Spot a bad config early? Stop it. See a promising one? Clone it and tweak knobs on the fly, no restart needed.
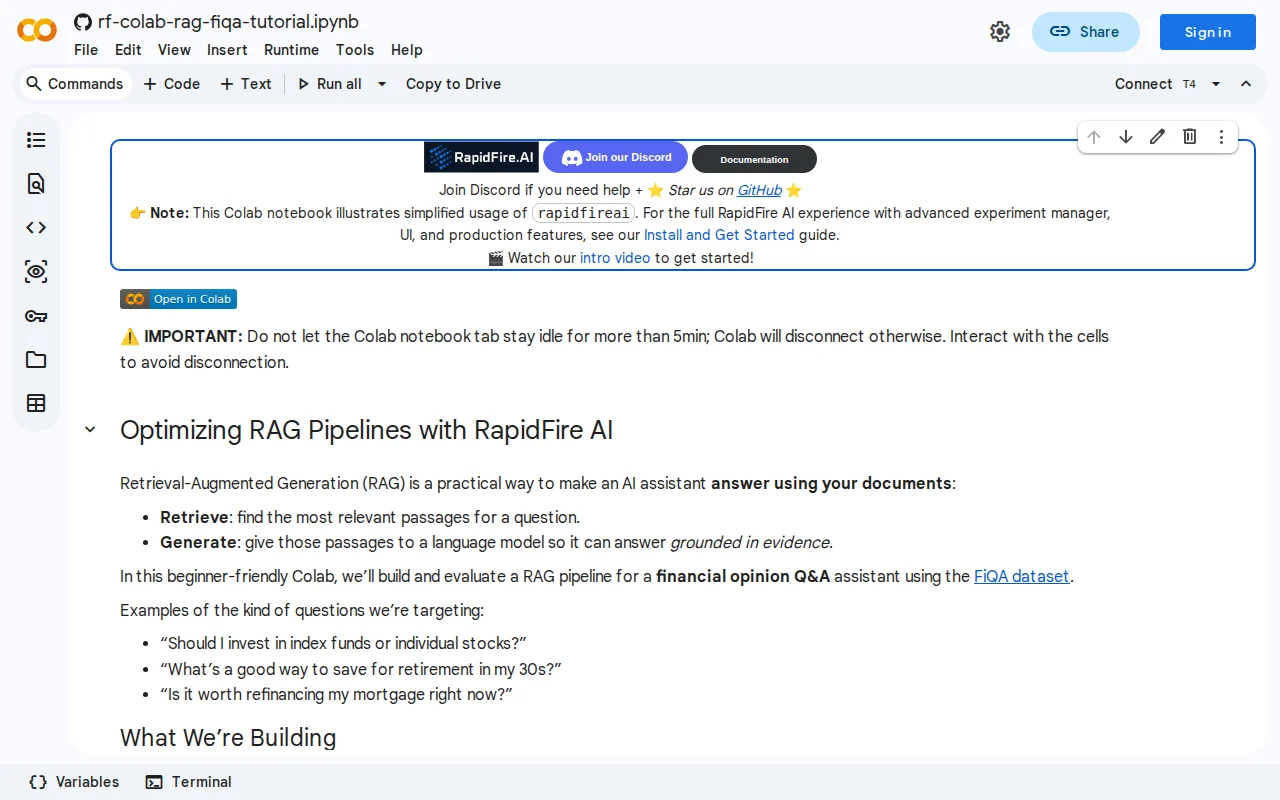
On a beefy machine you can comfortably run 100+ configs in a single experiment. Want to see it in action without installing anything? We have a Google Colab tutorial that runs 4 RAG retrieval configs in parallel on a free Colab GPU, zero local setup, under 2 minutes to get started. It builds a financial Q&A pipeline on the FiQA dataset, grid-searches over chunk sizes and reranker settings, and shows live metrics with confidence intervals as the configs run. If you're only calling OpenAI or other closed APIs, you don't even need a GPU at all.
Colab: https://colab.research.google.com/github/RapidFireAI/rapidfi...
Key features:
- pip install rapidfireai, pure Python, works on CPU-only, single-GPU, or multi-GPU
- Wraps LangChain for retrieval/reranking, supports vLLM + OpenAI for generation
- Interactive Control (IC) Ops: stop, resume, clone-modify configs mid-run from a dashboard or notebook
- Online aggregation with confidence intervals for statistically informed early-stopping decisions
- Grid search and random search over any knob (chunk size, top-k, reranker model, prompt template, generator params, etc.)
- MLflow-based metrics dashboard with real-time plots
Example speedup: 16 RAG configs x 400 queries at ~10s/query takes ~18 hours sequentially. With RapidFire AI + IC Ops (stop poor performers early, clone winners), we got it down to ~4 hours on the same machine, a 4.7x improvement while exploring more configs and reaching better final metrics.
Docs: https://oss-docs.rapidfire.ai
Tutorial notebooks (FiQA financial QA, GSM8K math reasoning, SciFact claim verification): https://github.com/RapidFireAI/rapidfireai/tree/main/tutoria...
Github: https://github.com/RapidFireAI/rapidfireai
We'd love feedback on what knobs/integrations matter most to you. Happy to answer questions here.
Multi-cloud GPU orchestration in one command beats provisioning each provider separately.
16-24x faster RAG iteration via shard-based concurrent execution with live control.
Tree search over git worktrees beats Karpathy's greedy hill climb for code optimization.
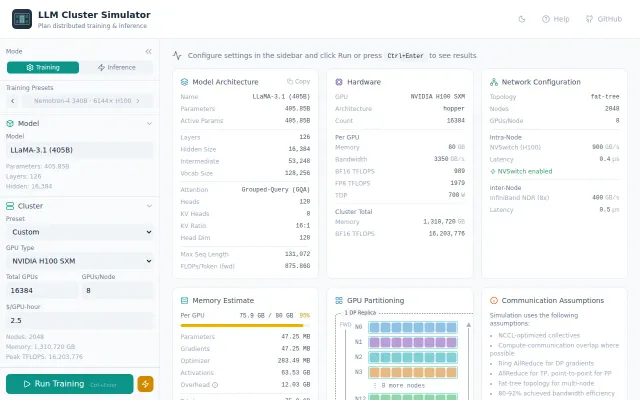
Estimates LLM training MFU, memory, timeline across 70 models and parallelism strategies—genuinely useful before GPUs commit.
Embedding anomaly detection cuts attack success from 95% to 20%.
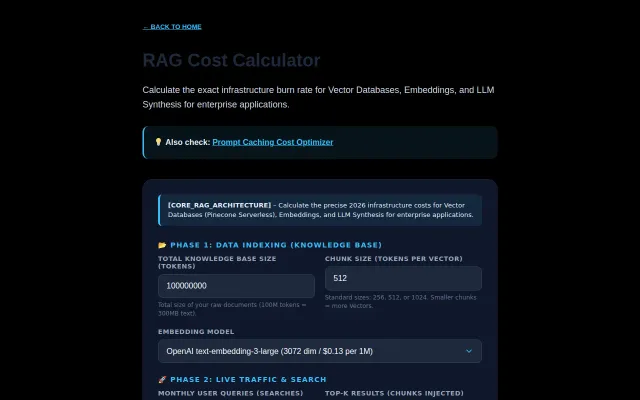
Breaks down hidden RAG costs like vector storage overhead and HNSW indexing fees.