AI/ML●●Solid
Llamactl – Self-hosted LLM manager with OpenAI-compatible routing
Multi-backend LLM manager when Ollama and LM Studio already handle this.
Solve My ProblemNiche Gem
lordmathis
202mo ago
Stop configuring your AI stack. Start using it. One command brings a complete pre-wired LLM stack with hundreds of services to explore.
Finally one CLI for Ollama, llama.cpp, and vLLM instead of three separate tools.
ML engineers, developers running local LLMs, AI infrastructure teams
Ollama CLI · llama.cpp · Hugging Face CLI
One notable added feature is ability to manage all my LLMs with a single CLI.
# list all models harbor ls # pairs well with jq harbor ls --json # Ollama harbor pull qwen3.5:35b # llama.cpp harbor pull unsloth/Qwen3.5-35B-A3B-GGUF:Q8_0 # vllm (HuggingFace Hub cache) harbor pull Qwen/Qwen3.5-35B-A3B
# Remove any of the models by the same id # used to pull it harbor rm <id>
Hopefully it'll be useful for someone too.
Multi-backend LLM manager when Ollama and LM Studio already handle this.
Found llama.cpp loading models twice in RAM — fixed with host_ptr, 74% reduction.
Useful tutorial, but llama.cpp docs and Ollama already cover most of this.
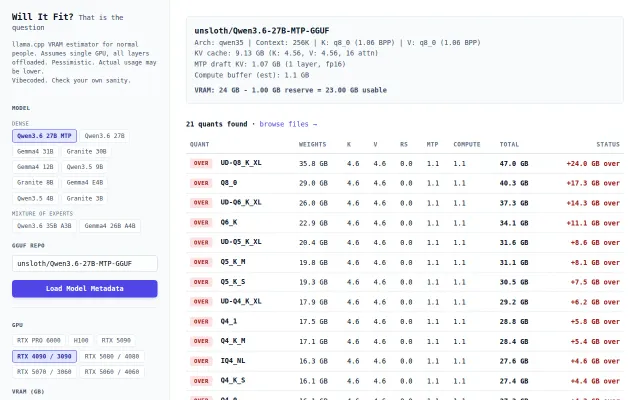
Opinionated llama.cpp VRAM calculator that outputs ready-to-run server commands.
One YAML config for three backends when Ollama already handles llama.cpp alone.
Article promising 2026 tech but just tells you to use standard Ollama.