Developer Tools●●Solid
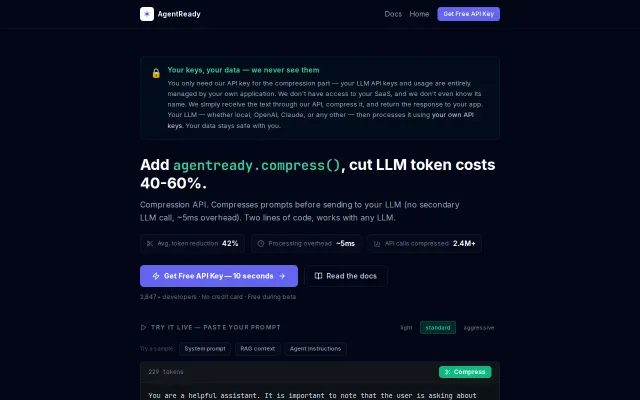
I built a proxy that cuts LLM costs 40-60% – no AI involved
Prompt compression API cuts token bills 40-60%, integrates in two lines.
Solve My ProblemSlick
christalingx
213mo ago
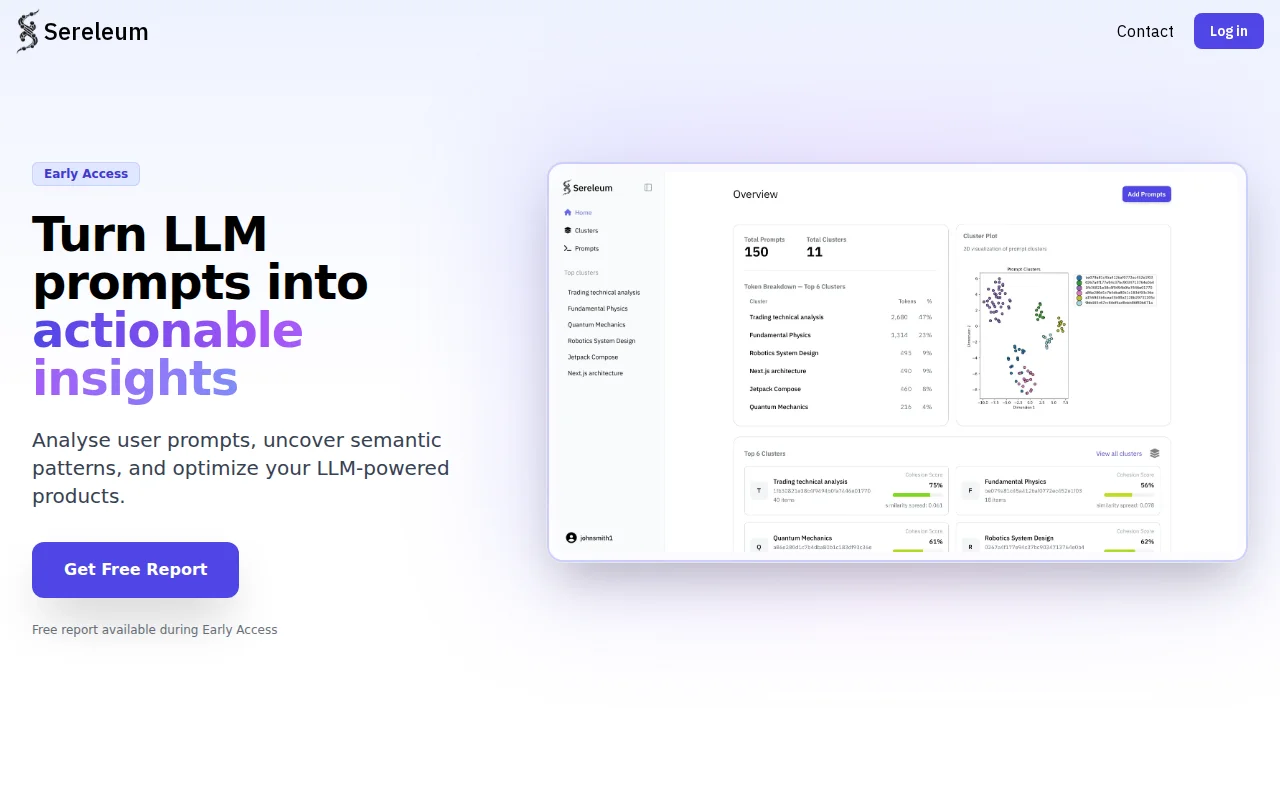
Prompt clustering with cost attribution when LangSmith already does observability.
Teams building LLM-powered products
LangSmith · Helicone · Arize Phoenix
Prompt compression API cuts token bills 40-60%, integrates in two lines.
Zero-agent cost analyzer that beats Kubecost on simplicity for quick audits.
Read-only GPU waste scanner finds 20-40% cluster spend waste without agents or sidecars.
One-command GPU waste scanner when Kubecost requires full Prometheus setup.
Local budget caps block requests before provider dashboards even update the bill.
Wire-protocol proxy means zero code changes to existing LLM clients.