Developer Tools●●Solid
CLI for crawling documentation sites into Markdown with defuddle
No-browser docs crawler using defuddle when Firecrawl and JinaAI already exist.
Ship ItSolve My Problem
nistuley
5016d ago

Cloudflare /crawl API powers nostalgic newspaper layouts for Hacker News and friends.
Tech news readers who enjoy nostalgic print formats
Cloudflare /crawl API demos · RSS readers · Morning Brew
It runs periodic crawls, picks up the top stories, and lays them out in a classic broadsheet format: top story, trending section, briefs, etc. Basically a daily edition of your favorite tech site.
Nothing serious, just a weeknight project to play with Cloudflare's /crawl API and a few of their other tech offerings (workers, D1, etc.). I'm not in any way sponsored by CF, but if you're from CF and you're reading this I really dig your stack and you should give me credits to fund these dumb projects thank you very much.
Home page: https://crawltimes.com/
No-browser docs crawler using defuddle when Firecrawl and JinaAI already exist.
No-browser doc crawler when JinaAI and Firecrawl already dominate this space.
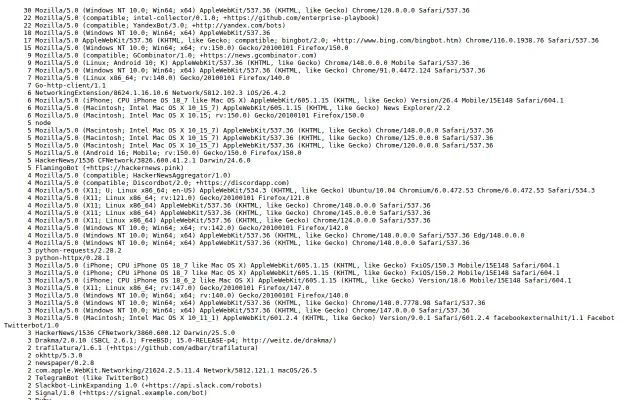
Live feed of crawler user agents hitting HN right now.
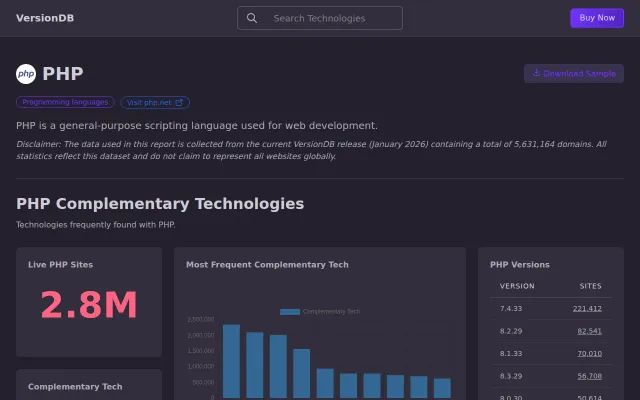
Crawled 5.6M sites, but tech stack distribution dashboards already exist (BuiltWith, Wappalyzer).
Finally sees the bot traffic GA4 filters out, with citation attribution.
Docs chatbot for static sites—but Mendable, Librarian, and ChatBot already own this space.