Developer Tools●●Solid
PreApply – Terraform plan analyzer with blast radius and risk scoring
Deterministic Terraform risk scorer beats AI guessing for deploy safety.
Solve My ProblemBig Brain
akileshthuniki
124mo ago
Prompt CVE tracking is clever, but LangSmith and Arize already cover this ground.
ML engineers and AI product teams shipping prompts to production
LangSmith · PromptLayer · Arize Phoenix
It wasn’t a jailbreak — just phrasing I hadn’t anticipated. The prompt looked fine. It passed code review. It failed in production.
That made me realize how little tooling exists between “write a prompt” and “ship it.”
We have linters for code. We have type checkers. We have static analysis.
For prompts, we mostly have vibes.
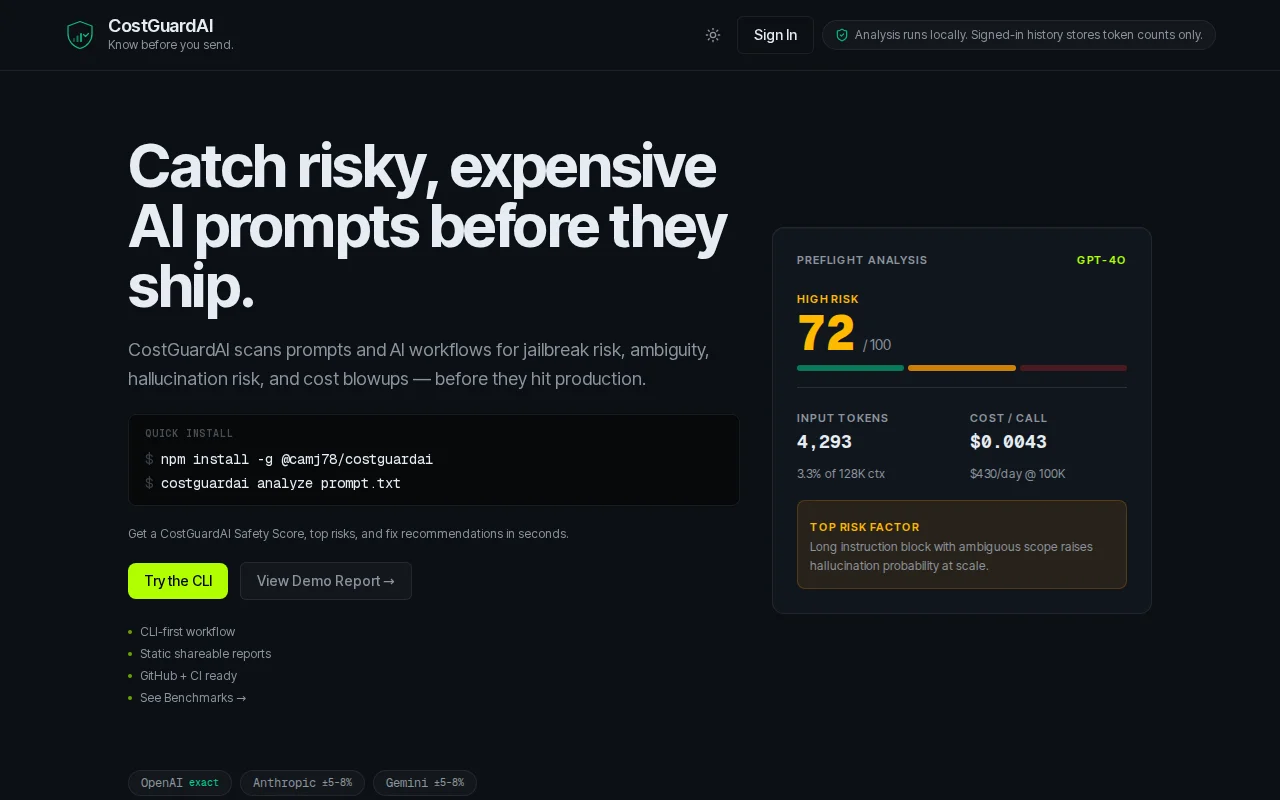
So I built CostGuardAI.
npm install -g @camj78/costguardai costguardai analyze my-prompt.txt
It analyzes prompts across a few structural risk dimensions: - jailbreak / prompt injection surface - instruction hierarchy ambiguity - under-constrained outputs (hallucination risk) - conflicting directives - token cost + context usage
It outputs a CostGuardAI Safety Score (0–100, higher = safer) and shows what’s driving the risk.
Example:
CostGuardAI Safety Score: 58 (Warning)
Top Risk Drivers: - instruction ambiguity - missing output constraints - unconstrained role scope
The scoring isn’t trying to predict every failure — it’s closer to static analysis: catching structural patterns that correlate with prompts breaking in production.
If you want to see output before installing: https://costguardai.io/report/demo https://costguardai.io/benchmarks
I’m a solo founder and this is still early, but it’s already caught real issues in my own prompts.
Curious what HN thinks — especially from people working on prompt evals or LLM safety tooling.
Deterministic Terraform risk scorer beats AI guessing for deploy safety.
Static scanner catches prompt injections in code before runtime, unlike runtime guards.
Deterministic prompt linter flags injection, exfiltration, obfuscation before LLM runs—treats prompts as executable code.
Published research with DOI beats yet another prompt engineering wrapper.
Detects sycophancy and jailbreak drift in LLMs without needing model weights.
Task-level automation risk scores for every U.S. job, grounded in BLS and O*NET.