AI/ML●●●Banger
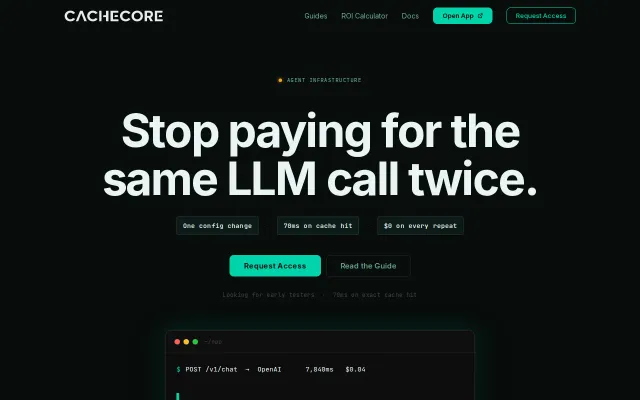
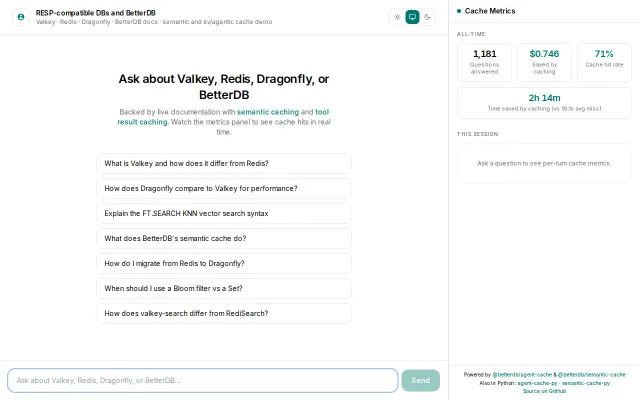
CacheCore – semantic agent caching with dependency invalidation
Semantic caching with dependency invalidation beats standard Redis wrappers for agent costs.
Big BrainSolve My Problem
fabriziorocco
241mo ago
The spec-driven environment for AI coding agents, where your planning becomes lasting, shared project context.
Commit-time indexing beats runtime scanning, but Cursor already indexes your codebase.
Developers using Claude Code, Codex CLI, or Gemini CLI
Cursor · Sourcegraph · Continue
With this approach a script runs once at commit time, reads each source file, and builds a semantic map; feature names pointing to files, exports, and API channels. That map gets committed alongside your code as a single JSON file. When an AI agent needs to find something, it queries one keyword and gets back the exact files and interfaces in under a millisecond.
What you gain: AI agents that navigate your codebase like they wrote it. No context wasted on irrelevant files. No missed connections between a service and its controller. And since the map regenerates automatically on every commit, it never falls out of sync. I added this to my open sourced agentic development platform, feel free to examine it or use it. Any ideas or contributions are always welcome.
Semantic caching with dependency invalidation beats standard Redis wrappers for agent costs.
Visual codebase map with magnetic-pull retrieval, but Sourcegraph and Cody already solve this.
Tool result caching for agents when GPTCache and LangChain already do semantic caching.
Blast radius detection before AI edits code, competing with Cursor's codebase awareness.
Yet another HTML preprocessor when Jina AI and Firecrawl already exist.
Visual codebase maps when Cursor and Sourcegraph Cody already do this.