AI/ML●●Solid
Three new models by KittenML. <25 MB Open-source TTS. Highly Expressive
Sub-25MB TTS models when Coqui and glow-TTS already dominate the space.
Niche GemShip It
rohan_joshi
463mo ago
State-of-the-art TTS model under 25MB 😻
SOTA expressivity at 14M parameters beats cloud models for on-device TTS.
Embedded developers and mobile app builders needing on-device speech
Piper TTS · Coqui TTS · Silero TTS
The largest model has the highest quality. The 14M variant reaches new SOTA in expressivity among similar sized models, despite being <25MB in size. This release is a major upgrade from the previous one and supports English text-to-speech applications in eight voices: four male and four female. Most models are quantized to int8 + fp16, and they use ONNX for runtime. The model is designed to run anywhere eg. raspberry pi, low-end smartphones, wearables, browsers etc. No GPU required! This release aims to bridge the gap between on-device and cloud models for tts applications. Multi-lingual model release is coming soon.
On-device AI is bottlenecked by one thing: a lack of tiny models that actually perform. The goal is to open-source more models to run production-ready voice agents and apps entirely on-device. Would love your feedback!
Sub-25MB TTS models when Coqui and glow-TTS already dominate the space.
Sub-sentence TTS streaming beats Piper/Sherpa-ONNX latency by token-level triggering on CPU.
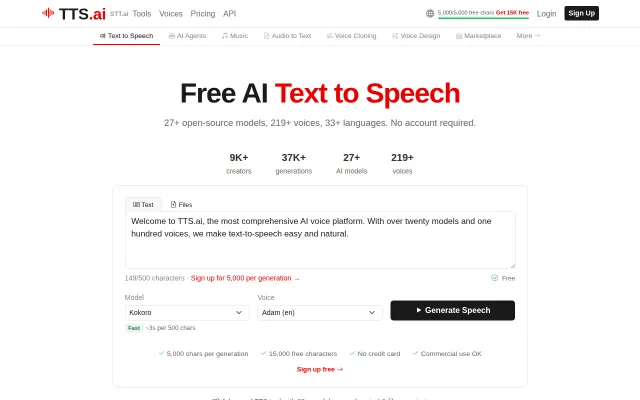
Twenty-seven open-source TTS models in one UI with no signup required for the free tier.
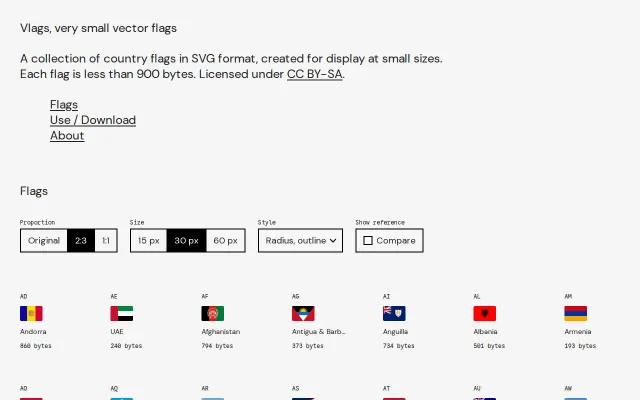
SVG flags under 900 bytes, but flag libraries are a solved category.
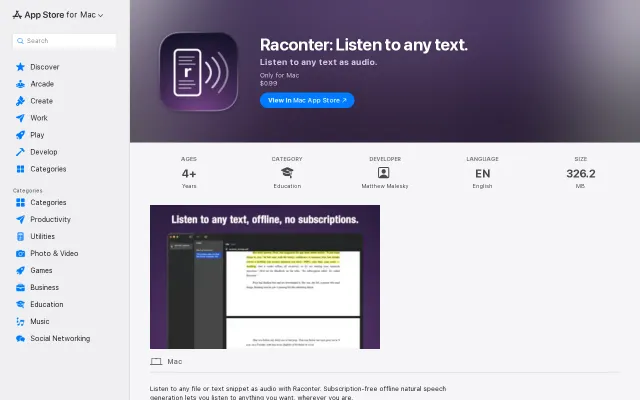
Runs Kokoro TTS offline for $0.99, undercutting subscription readers like NaturalReader.
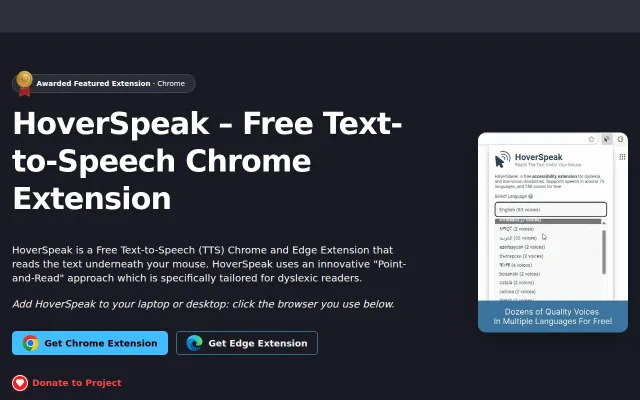
Point-and-read without selection beats Natural Reader's click-to-speak workflow.