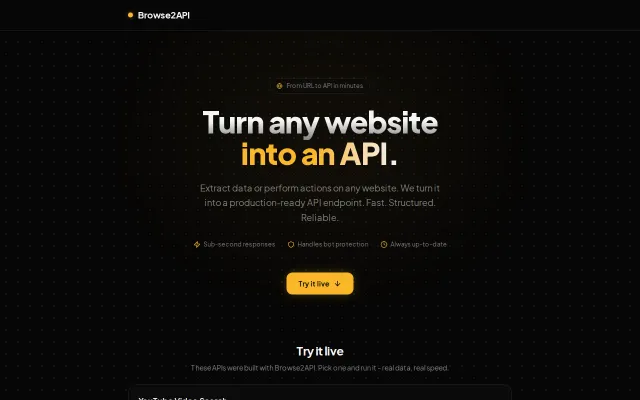
Developer Tools●●Solid
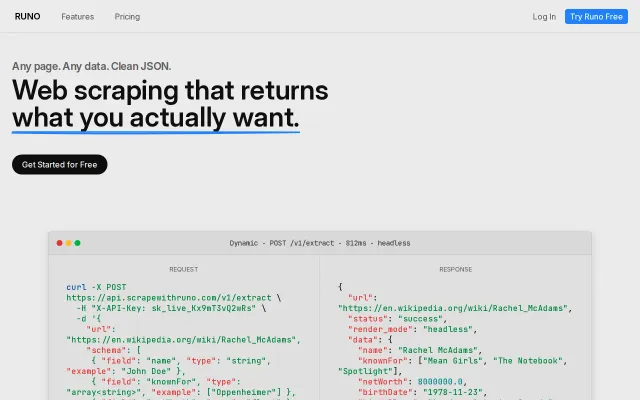
Runo – Scraping API that returns typed JSON, not raw HTML
Schema-driven extraction beats maintaining brittle CSS selectors.
Solve My ProblemSlick
barebearcountry
4028d ago
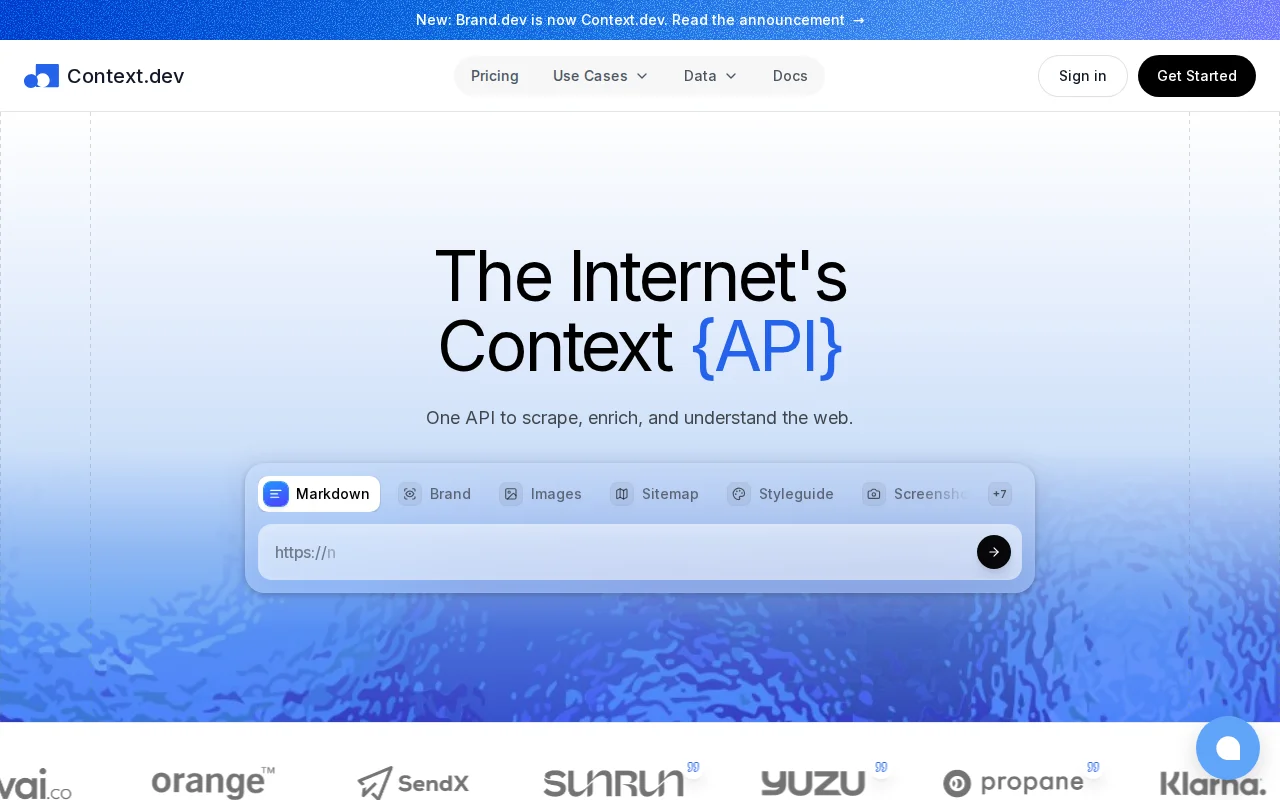
Web scraping API with brand enrichment when JinaAI and Firecrawl already dominate.
AI developers, LLM application builders, data enrichment needs
JinaAI Reader · Firecrawl · ScraperAPI
My name is Yahia, I've been working on scraping products for a long time and maintain a couple of free sites in my spare time (E.g. knifegeek.io)
What prompted this is i've rebuilt scraping infra at every company I've started and finally just made it a product.
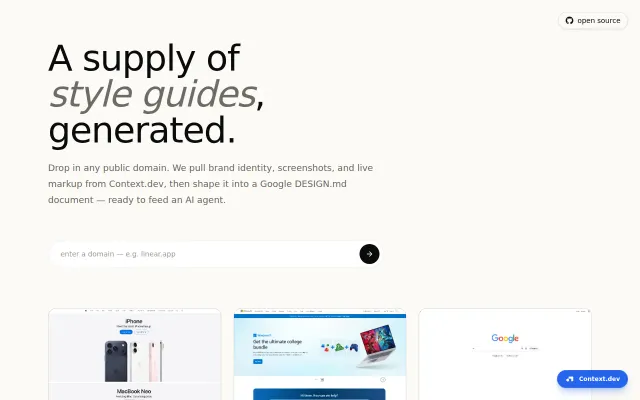
Pass a URL, get clean markdown, html, images, sitemap or pass a domain, get logos, colors, socials, industry data.
Goal is to offer a better service than VC funded competitors at a fraction of the cost.
Stealth is included and automatic at no additional cost (normally an upcharge by alternatives).
Would love your honest thoughts.
Schema-driven extraction beats maintaining brittle CSS selectors.
Context.dev scraping is a clever hack for feeding brand data to AI agents.
CLI wrapper for Firecrawl when the API and SDKs already work fine.
Web scraping as a service, but Firecrawl and ScrapingBee already own this.
Extracts and deduplicates business data from Google Maps and Yelp and handles Maps' infinite scroll using Playwright so you can export consistent JSON/CSV without running infrastructure. Technically competent on scraping details, but the Actor ships with no README, has almost no user traction, and sits in a crowded category — expect manual tuning, rate-limit/legal caveats, and data freshness issues.
Browser-driven API generation beats manual scrapers, but Apify, Cheerio, and Puppeteer already solve this.