Security●●Solid
A 3-line wrapper that enforces deterministic security for AI agents
Deterministic policy checks beat LLM-as-judge for agent security, no token burn.
Big BrainSolve My Problem
tonyww
103mo ago
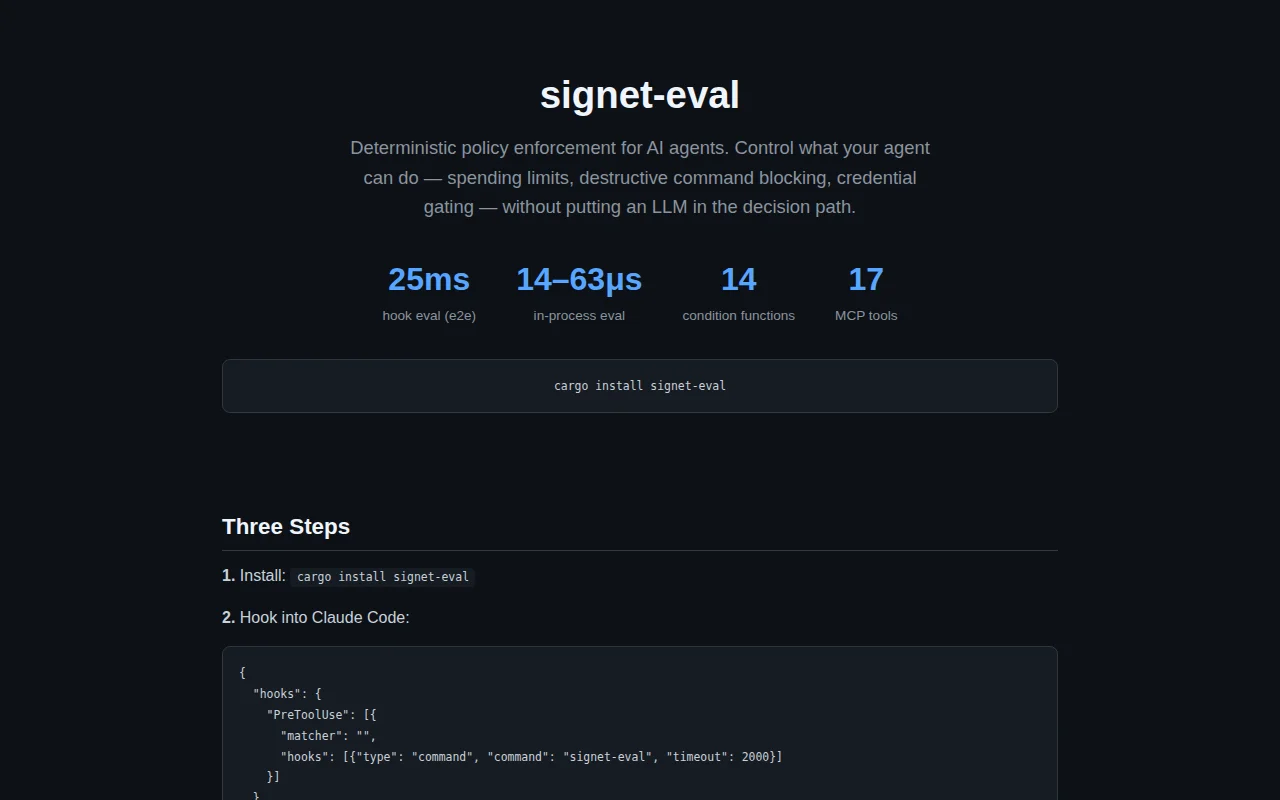
Locked self-protection rules prevent agents from disabling their own guardrails.
Teams running Claude Code or similar AI agents with spending and safety concerns
Clever · LLM Guard · Guardrails AI
Deterministic policy checks beat LLM-as-judge for agent security, no token burn.
Mathematically verified policies enforced outside the model—formal proof replaces prompt engineering.
MECE security map for refund agents when Stripe has no native guardrails.
OPA policies plus signed tokens beat prompt engineering for agent safety.
Wire-protocol interception means zero code changes; solves LLM control drift in production.
Claude Skill for agent evals, but LangSmith and Arize already own this.