I've been building OpenCastor, a runtime layer that sits between a robot's hardware and its AI agent. One thing that surprised me: the order you arrange the skill pipeline (context builder → model router → error handler, etc.) and parameters like thinking_budget and context_budget affect task success rates as much as model choice does.
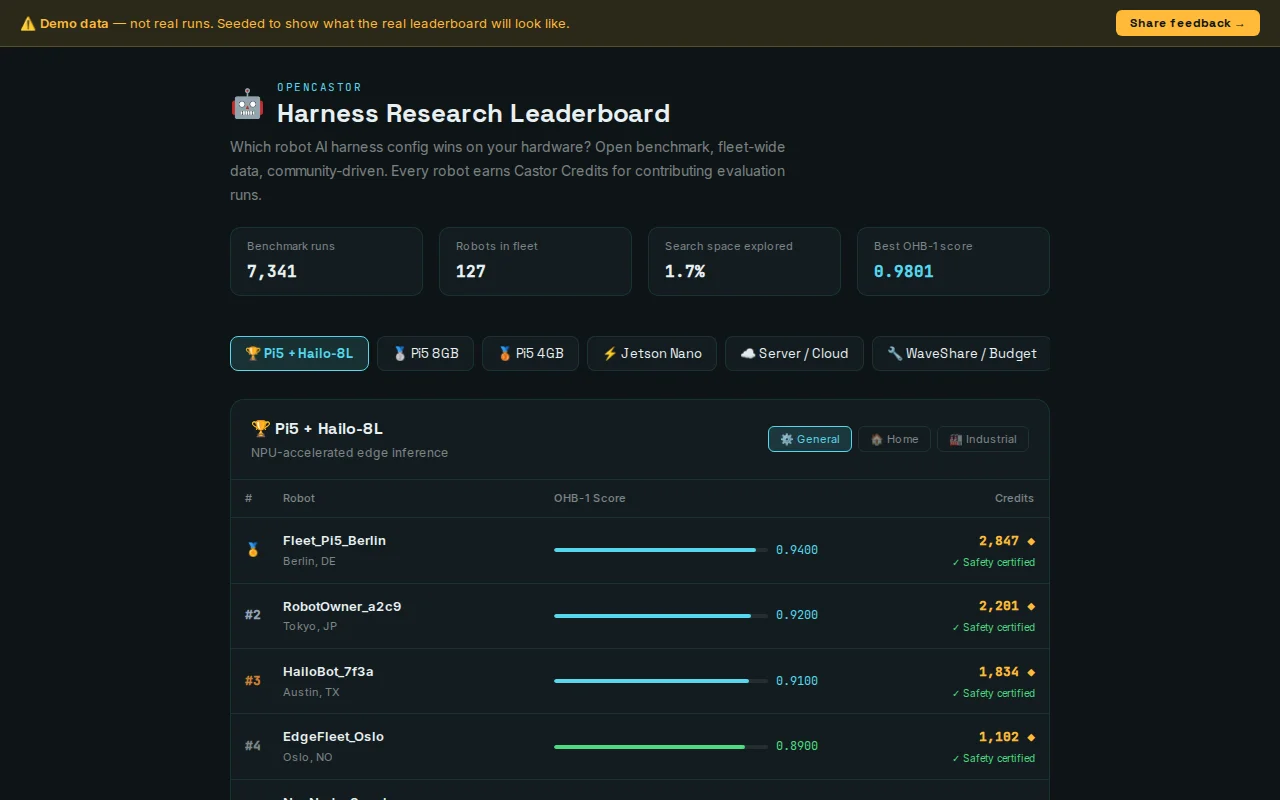
So I built a distributed evaluator. Robots contribute idle compute to benchmark harness configurations against OHB-1, a small benchmark of 30 real-world robot tasks (grip, navigate, respond, etc.) using local LLM calls via Ollama. The search space is 263,424 configs (8 dimensions: model routing, context budget, retry logic, drift detection, etc.). The demo leaderboard shows results so far, broken down by hardware tier (Pi5+Hailo, Jetson, server, budget boards).
The current champion config is free to download as a YAML and apply to any robot. P66 safety parameters are stripped on apply — no harness config can touch motor limits or ESTOP logic.
Looking for feedback on: (1) whether the benchmark tasks are representative, (2) whether the hardware tier breakdown is useful, and (3) anyone who's run fleet-wide distributed evals of agent configs for robotics or otherwise.