AI/ML●●●Banger
Glq LLM quantization using E8 lattice
E8 lattice codebooks beat GPTQ at 2-4 bpw with fused CUDA kernel skipping weight materialization.
WizardryBig Brain
acd
2013d ago
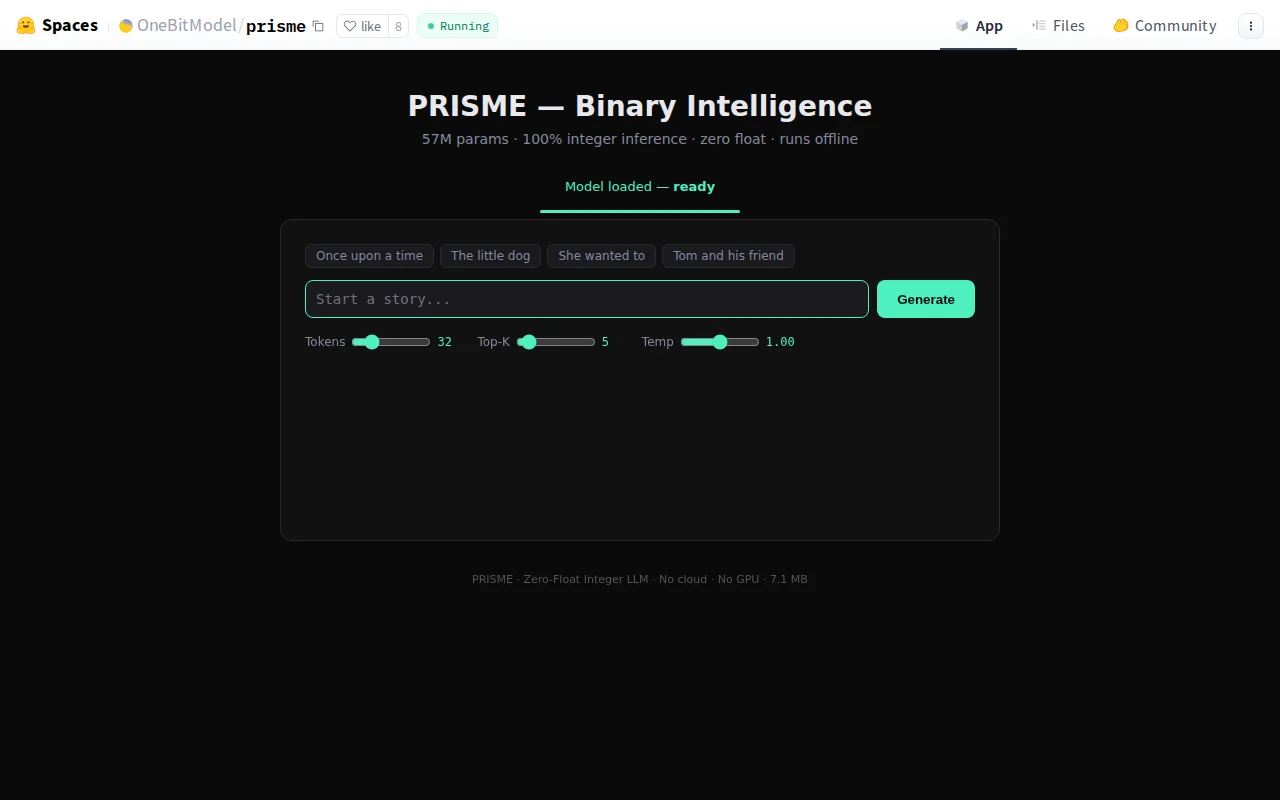
7MB binary-weight LLM runs entirely on integer math with no floating point unit.
Embedded Developers, Edge AI Engineers, Hobbyists
TinyLLM · WebLLM
E8 lattice codebooks beat GPTQ at 2-4 bpw with fused CUDA kernel skipping weight materialization.
3.9s cold starts vs 45s+ for quantized models—real infra pain solved tangibly.
Native ternary training beats post-training quantization for memory efficiency.
Detects sycophancy and jailbreak drift in LLMs without needing model weights.
SQLite-based LLM inference hitting 210MB RSS beats OS paging with deterministic memory control.
Streams LLM weights from CD-ROM during inference to fit 77MB models in 32MB RAM.