Productivity●Mid
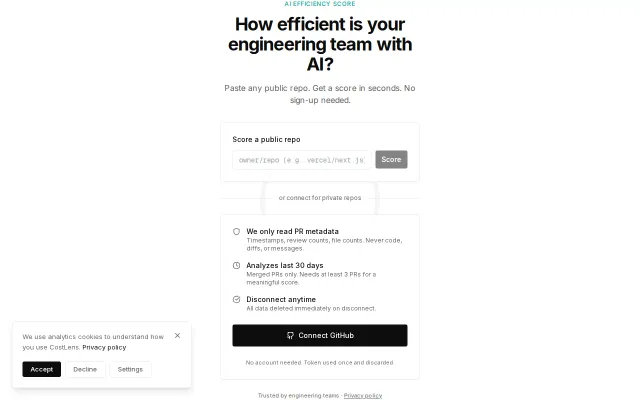
AI Efficiency Score – paste any GitHub repo, get a score in seconds
Vanity metric generator for engineering leaders who love dashboards.
Ship It
j_filipe
201mo ago
Yet another engineering metrics tool, but Claude scoring six dimensions is transparent.
Engineering managers and CTOs tracking team velocity and code quality
LinearB · Waydev · CodeRabbit
Every merged PR gets scored 0–100 by Claude across six dimensions: scope (0–20), architecture (0–20), implementation (0–20), risk (0–20), quality (0–15), perf/security (0–5). Six dimensions added up, then scaled by change size — a 10-line fix scores lower than a 500-line refactor even at the same complexity. Full formula at gitvelocity.dev/scoring-guide.
After scoring 46,000+ PRs across TypeScript, Python, Rust, Go, Java, Elixir, and more, some things surprised us:
Big PRs don't automatically score high. An 800-line migration with low complexity scores worse than a 200-line architectural change. Size gets you the full multiplier, but the base score still has to earn it.
You can't score well without tests. The quality dimension (0–15) won't give you points without test coverage. At similar experience levels, this was the clearest separator between engineers.
Juniors started outscoring some seniors. They adopted AI tools faster and took on harder problems. Once they could see their own scores, they aimed higher.
We score AI-generated code the same as human-written code. Code is code. An engineer who uses AI to ship more complex work faster is more productive, and their scores reflect that.
Scoring consistency was the hardest technical problem. Without reference examples anchoring each dimension, Claude's scores drifted 15+ points between runs. With 18 calibrated anchors (three per dimension at low/mid/high), we got it down to 2–4 points on the same PR.
The thing we didn't expect was behavioral. We call it the Fitbit effect — the tool doesn't make you ship better code, but seeing the score does. Engineers started referencing their own scores in 1:1s unprompted, because the numbers matched what they already felt about their work. A junior who shipped a tricky concurrency fix could point to a score that proved it wasn't "just a small PR."
We recently added team benchmarks (gitvelocity.dev/demo/benchmarks). Once you're scoring PRs, you can see how your team compares to others across the dataset — about 1,000 engineers on 60 teams so far. Headline's team ships faster than roughly 95% of them, which was nice to confirm but also made us wonder who the other 5% are. The competitive angle surprised us: teams that were skeptical about individual scores got genuinely curious once they could measure themselves against the field.
Every score is fully visible to the engineer who wrote the PR, with per-dimension breakdowns and reasoning. There's no hidden dashboard that management sees and engineers don't.
Free, BYOK (your Anthropic API key). We default to Sonnet 4.6, which scores nearly as well as Opus 4.6 at a fraction of the cost — but you can switch models if you want. Pennies per PR either way. No source code stored, diffs analyzed and discarded. Works with GitHub, GitLab, and Bitbucket.
Ask me anything about the scoring methodology, how we solved calibration, or what it was actually like rolling this out to a team.
Vanity metric generator for engineering leaders who love dashboards.
Credit-score-style health metric is clever, but survey-only MVP lacks clinical validation and differentiation.
SDLC governance scanner that maps GitHub activity to SOC 2 and ISO 27001 controls.
SPI scoring formula is clever but Snyk and Semgrep already cover these 10 engines.
Stack memory learns your preferences across sessions — FastAPI, typed code, SQLite.
Deduping PRs and scoring them with 20 heuristic signals is a concrete, useful idea — especially the scope-coherence signal and embedding auto-fallback for providers without embeddings. The repo supports CLI, a persistent server, GitHub App integration and an explicit --model flag for provider flexibility, but it's still early and adoption/UX examples (ranked output, workflows) are thin — promising engineering scaffolding that needs real-world validation.