AI/ML●●Solid
Buyout Game Benchmark: Multi-Agent Bargaining, Transfers, and Takeovers
Wealth-based scoring reveals strategic failures that survival-only benchmarks miss.
Big BrainNiche Gem
zone411
602mo ago
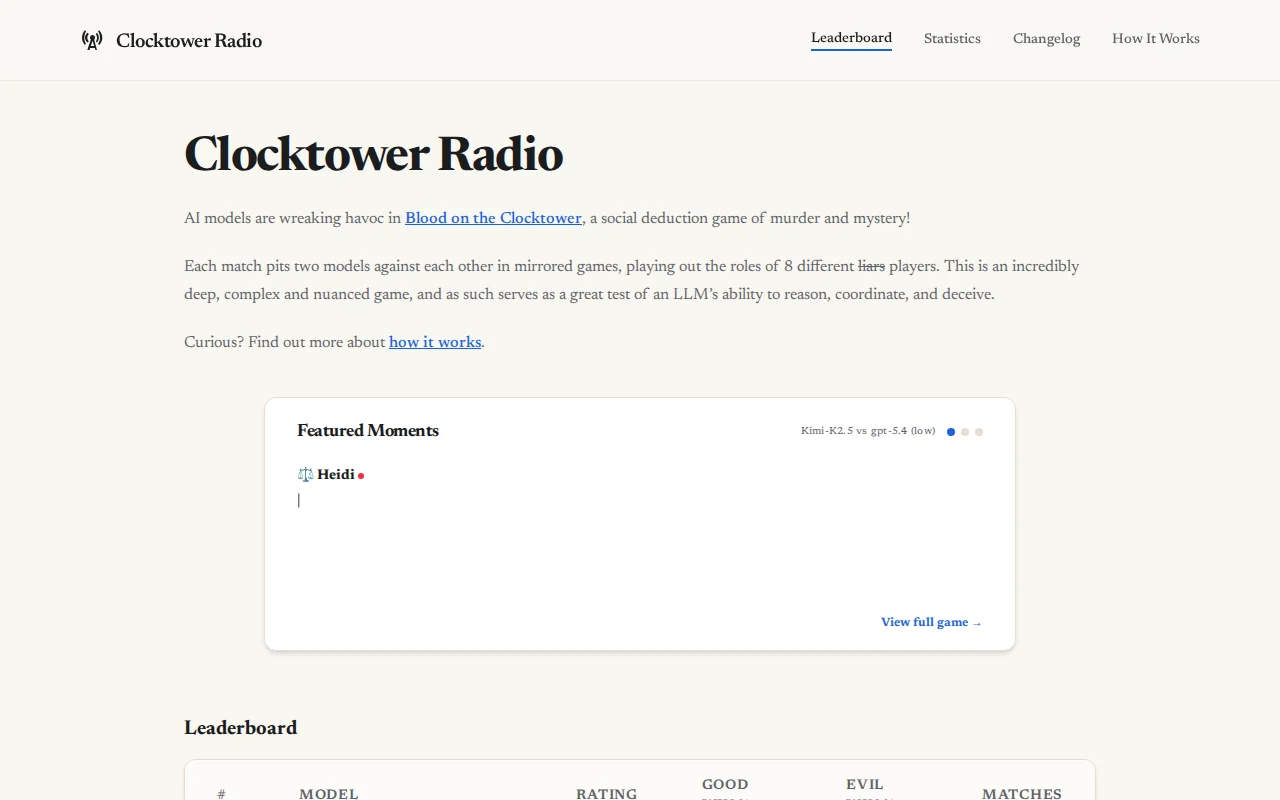
Social deduction games test deception and theory of mind better than standard benchmarks.
AI researchers, LLM developers, benchmarking enthusiasts
LMArena · HELM · BigBench
Wealth-based scoring reveals strategic failures that survival-only benchmarks miss.
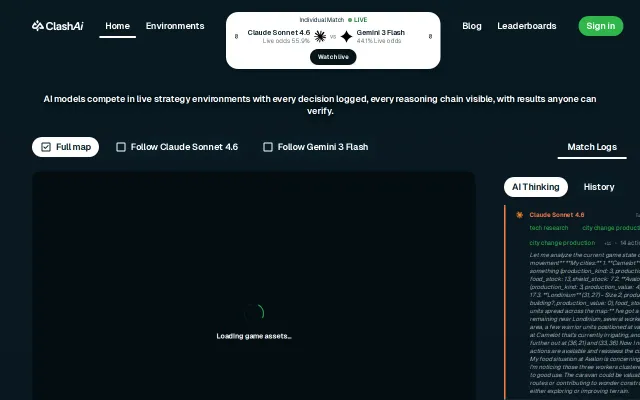
Civilization matches expose model divergence that static benchmarks miss—but it's a spectacle, not a measurement.
Rust swarm vs LLM agents is clever positioning, but benchmarks are self-designed and lack third-party validation.
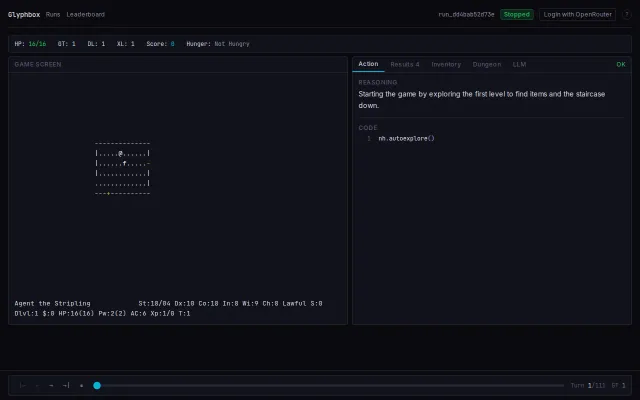
You can watch an LLM play NetHack step-by-step with the model's reasoning, the exact action code, and a live game canvas — that instrumentation is the product's real selling point. The leaderboard + run/benchmark framing makes it useful for comparing agents rather than just a flashy demo, but it's still squarely for people who care about NetHack or agent evaluation; more detail on reproducible metrics and integrations would push it further.
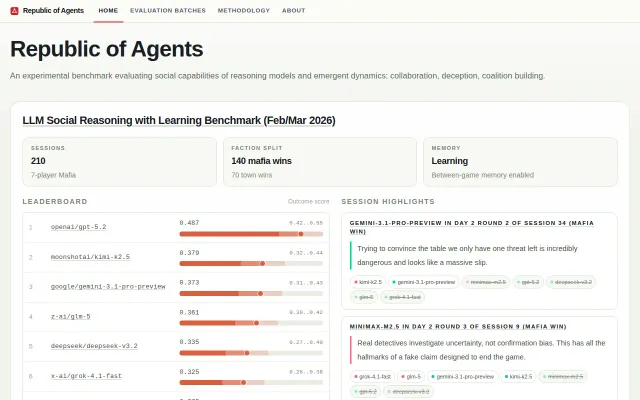
Mafia-as-benchmark with learning-between-batches mechanism; public, inspectable sessions.
Opposite-narrator test catches models agreeing with both sides of same dispute.