Developer Tools●●●Banger
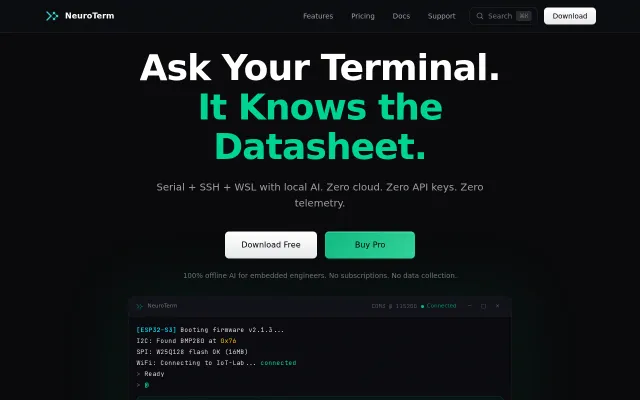
NeuroTerm – AI terminal for embedded devs (local LLM, local RAG)
Local LLM + RAG for datasheets beats cloud AI for proprietary firmware.
Solve My ProblemNiche GemShip It
0xecro1
113mo ago
Gemma Gem runs Google's Gemma 4 model entirely on-device via WebGPU — no API keys, no cloud, no data leaving your machine.
Local LLM agent with DOM tools running entirely in-browser via WebGPU.
Developers, privacy-conscious AI users
Cursor · Continue · Sourcegraph Cody
You get a small chat overlay on every page. Ask it about the page and it (usually) figures out which tools to call. It has a thinking mode that shows chain-of-thought reasoning as it works.
It's a 2B model in a browser. It works for simple page questions and running JavaScript, but multi-step tool chains are unreliable and it sometimes ignores its tools entirely. The agent loop has zero external dependencies and can be extracted as a standalone library if anyone wants to experiment with it.
Local LLM + RAG for datasheets beats cloud AI for proprietary firmware.
Runs multimodal screen memory on 4GB VRAM while Microsoft Recall requires high-end NPU.
Bundled llama.cpp means zero API keys, unlike Aider or Claude Code.
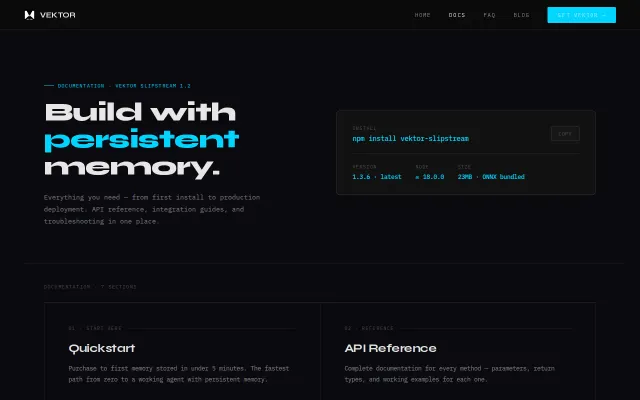
Local-first agent memory with SQLite graphs, but requires a license key.
Local Gemma 4 vision agent critiques UI continuously without sending screenshots to the cloud.
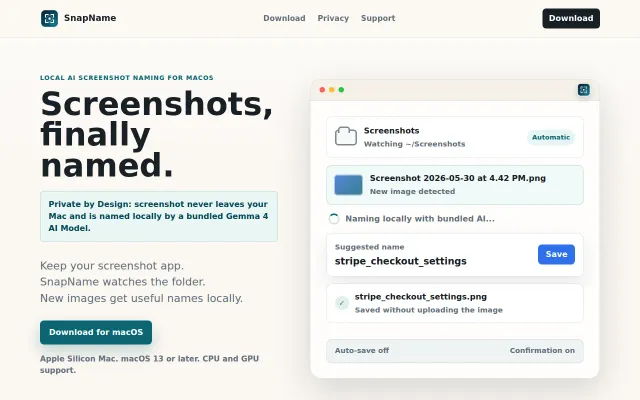
Bundles a 5GB Gemma 4 model locally to name screenshots without uploading.