AI/ML●Mid
My "home rig" for iterative attribute-weighted LLM benchmarking
Home rig for attribute-weighted benchmarking lacks the polish of established eval frameworks.
Ship It
yuvalhaim
211mo ago
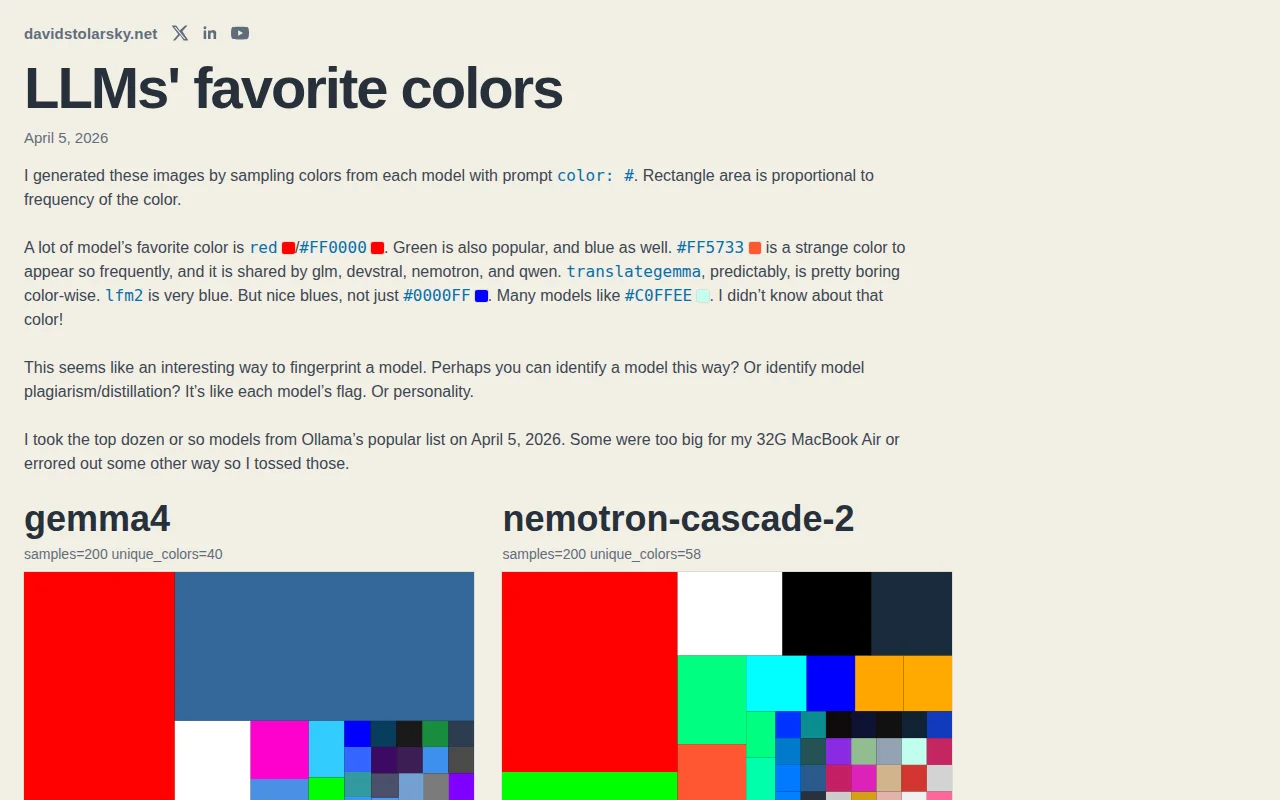
Sampling hex codes from 10 LLMs exposes bias patterns useful for fingerprinting.
AI researchers, LLM enthusiasts, curious developers
Home rig for attribute-weighted benchmarking lacks the polish of established eval frameworks.
Best text rendering in open-weight models with bounding box layout controls.
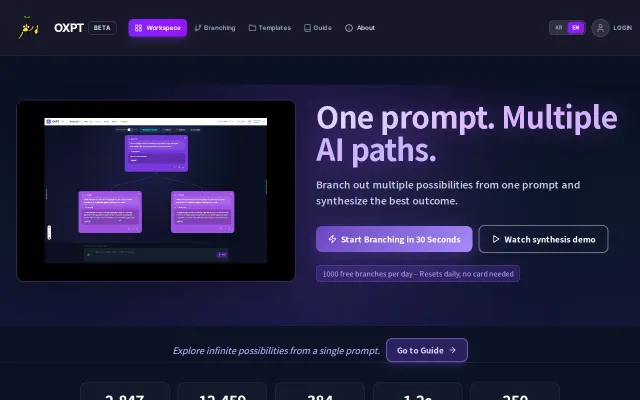
Beautiful node-based UI for prompt branching, but prompt iteration tools already exist everywhere.
Continual learning pipeline that fine-tunes weights from text feedback, real distributed execution options.
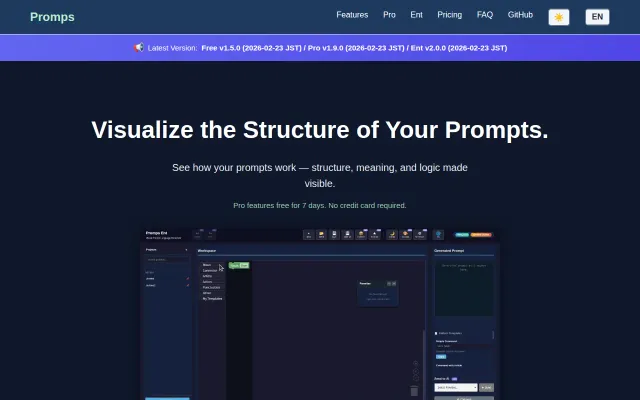
Blockly-based prompt editor beats text-only alternatives, but prompt builders already exist.
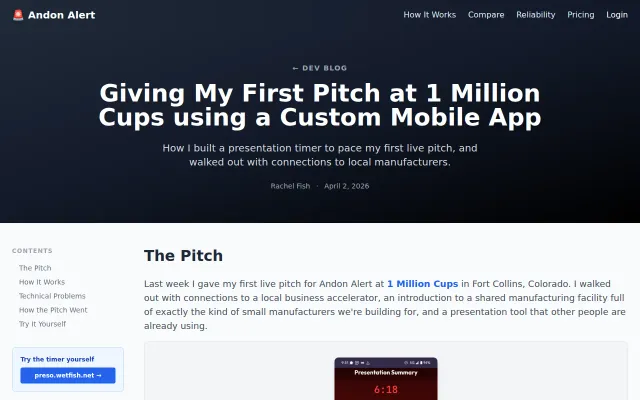
Gradient bands show pacing per slide — way more useful than a boring countdown timer.