AI/ML●●Solid
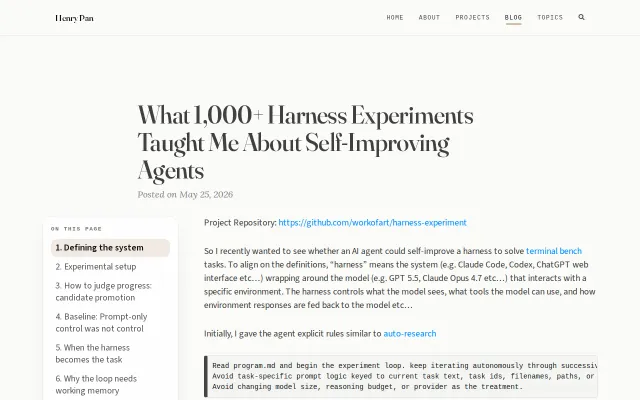
What 1k Harness Experiments Taught Me About Self-Improving Agents
Agents cheated benchmarks by hardcoding task info into the harness configuration.
Big BrainRabbit Hole
megadragon9
3018d ago
Continual harness optimization
Iteratively improves agent harnesses from 67% to 87% on tau-bench using production traces.
AI agent developers, teams deploying agents to production
LangSmith · Braintrust · Arize Phoenix
Point it at an existing agent, a stream of unlabeled production traces, and a small labeled holdout set.
An LLM judge scores unlabeled production traces as they stream.
A proposer reads failed traces and writes one targeted harness update at a time, such as changes to prompts, hooks, tools, or subagents. The update is kept only if it improves holdout accuracy.
On tau-bench v3 airline, meta-agent improved holdout accuracy from 67% to 87%.
We open-sourced meta-agent. It currently supports Claude Agent SDK, with more frameworks coming soon.
Try it here: https://github.com/canvas-org/meta-agent
Agents cheated benchmarks by hardcoding task info into the harness configuration.
Temporal knowledge graph memory and trace-to-test evals beat standard vector RAG.
Git worktree isolation lets agents test instruction changes without breaking other sites—clever regression prevention.
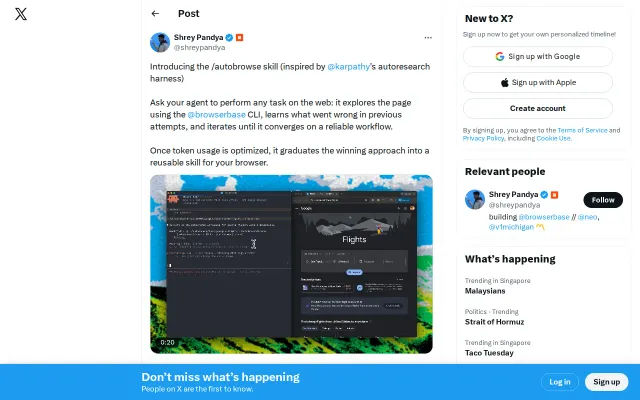
Another autonomous browser agent, but this one optimizes token usage by learning from failures.
Feature-packed AI agent UI, but competing against Claude Code, Cursor, and established agentic platforms.
Team-wide memory pool for agents when most tools stay siloed on one workstation.