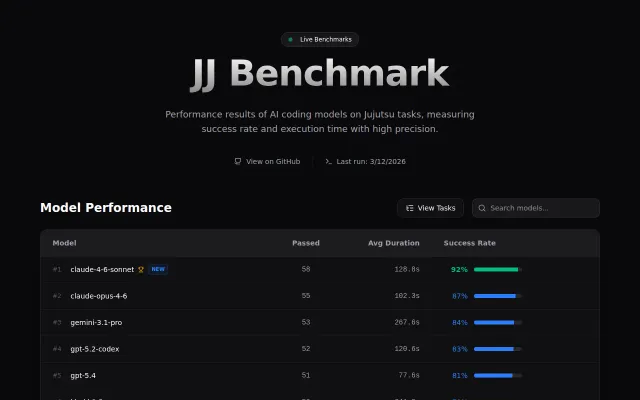
AI/ML●●●Banger
Synthetic corporate dataset generator for AI agent evaluation
Finally replaces the 25-year-old Enron corpus with deterministic org simulation.
Big BrainZero to One
jflynt76
303d ago
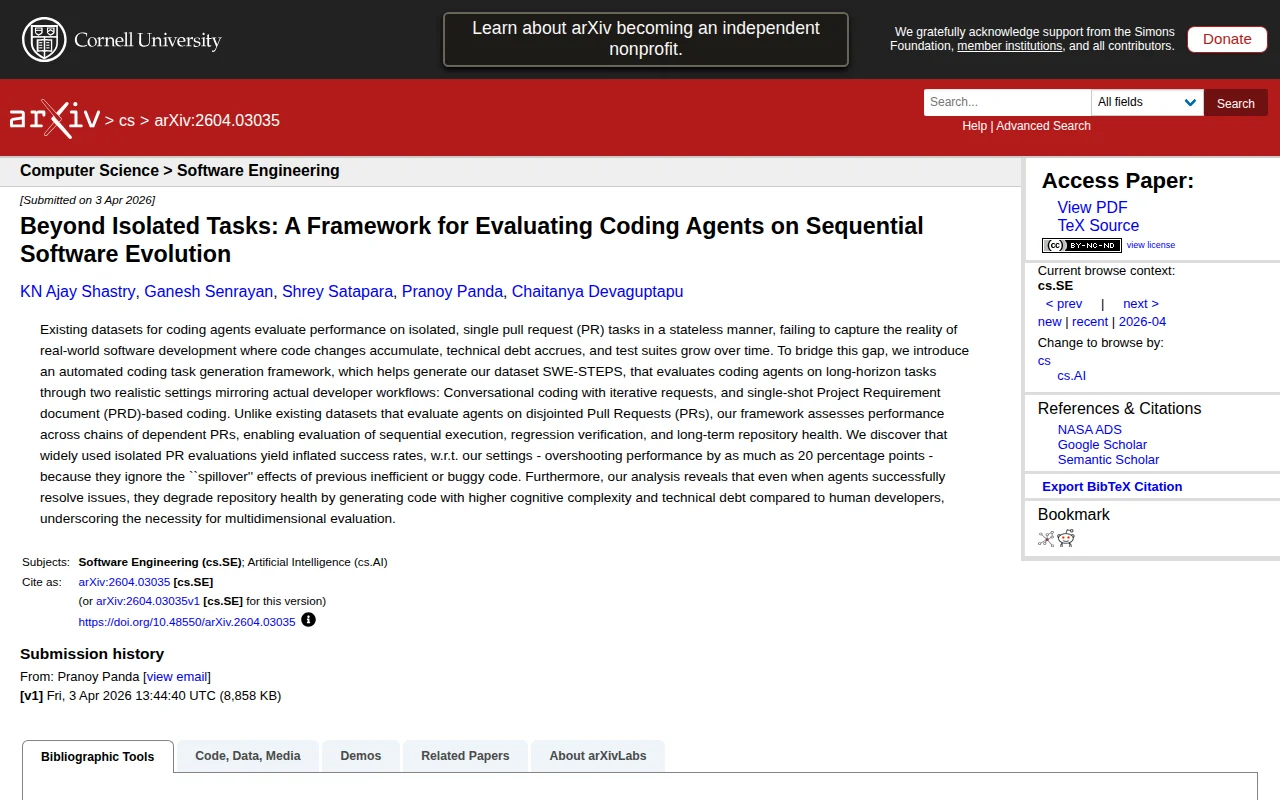
Exposes how current AI coding benchmarks inflate success rates by 20%.
AI researchers, LLM application developers, CI/CD engineers
SWE-bench · HumanEval · AgentBench
Finally replaces the 25-year-old Enron corpus with deterministic org simulation.
Persistent Python runtime keeps state alive across tool calls, unlike Claude Code's stateless tools.
Self-hosted alternative to Cursor and Continue with auditable agent playbooks.
Deterministic agent benchmarking with strict validation—unlike SWE-Bench, measures whether agents actually operate.
AI benchmarking for jj CLI when LMSys and HuggingFace already dominate the space.
Conformal prediction trained on 3K tasks hits 81% cost accuracy.