Developer Tools●●●Banger
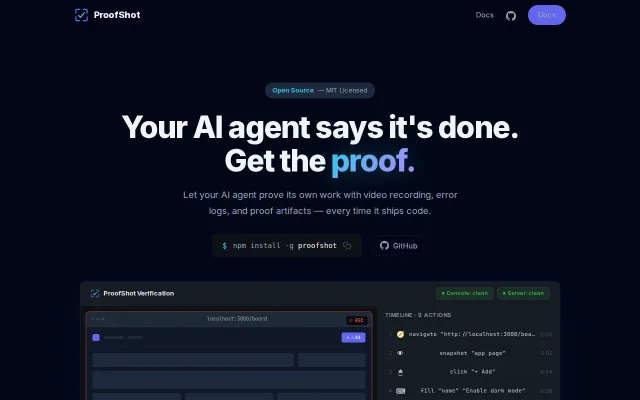
ProofShot – Give AI coding agents eyes to verify the UI they build
Finally, visual proof when your AI agent claims it finished the UI work.
Solve My ProblemZero to OneSlick
jberthom
1611062mo ago
Gives coding agents eyes for frontend work — visual QA and verification powered by Yutori Navigator.
Vision models catch UI bugs that Playwright selectors miss — built for AI agent workflows.
Developers using AI coding agents, frontend engineers, QA teams
Playwright · Percy · Applitools
They write “valid” HTML/CSS code but can still ship a broken layout, a clipped dropdown, or a page at the wrong URL. Playwright scripts can assert modal.isVisible() without knowing the modal is rendered off-screen.
Essentially, coding agents need “eyes” to verify their own UI work.
frontend-visualqa is a CLI + MCP server for Claude Code and Codex for visual testing, verification, and QA of a website.
You give it a URL and natural-language claims:
frontend-visualqa verify http://localhost:8000/dashboard.html \ --claims \ 'The API status indicator shows Active' \ 'The monthly quota progress bar is completely filled'
# → first claim passes, second fails (label says 100% but bar is ~65% full)
It catches visual<->DOM disagreements that selectors are blind to.You can also test interactive flows without hardcoded data:
frontend-visualqa verify 'http://localhost:8000/booking_form.html' \ --claims 'The date on the confirmation page matches the date selected on the calendar' \ --navigation-hint "Fill out the form with example data"
# → fails: fills the form, picks a date, books the slot, and catches an off-by-one date error on the confirmation page
The visual evaluation runs on n1, a VLM by Yutori that is post-trained specifically for browser interaction with RL on live websites. It navigates pages autonomously — so when a coding agent sends it to the wrong URL, n1 sees the wrong page, self-corrects, and reports this correction. On browser-use benchmarks n1 slightly outperforms Opus 4.6 and GPT-5.4 while running 2—3x faster at 4—5x lower cost: https://yutori.com/blog/introducing-n1How does this compare to?
1. Playwright CLI+MCP - Gold standard, but blind. - frontend-visualqa is the visual verification layer on top.
2. OpenAI Playwright skill / Claude + Dev-Browser - similar idea, but n1 is specifically trained for browser use (thus faster and cheaper), and the claim-based approach structures what to check rather than hoping the model notices everything. - Not locked to a TUI or IDE.
Known limitations: - Native <select> dropdowns render as OS-level widgets outside the viewport — n1 can't see or interact with them. Custom dropdowns work fine. - Small visual/numeric disagreements (red vs green status dot) are a known hard case. Improving with model updates.
Requires a Yutori API key (new accounts get free credits). DM me if you run out of credits.
Finally, visual proof when your AI agent claims it finished the UI work.
Generates audit trails for agent work, but Cursor custom instructions already do this.
Auto-discovers .db files so you can verify what your coding agent actually created.
Audit-ready AI agent that replays verified workflows instead of re-reasoning every time.
Catches AI-written code that looks right but breaks at runtime before merge.
Full VMs with bring-your-own-cloud pricing beat E2B's container lock-in.