Developer Tools●●●Banger
Helix – open-source self-healing back end for production crashes
Sentry-to-PR pipeline writes failing tests first, then fixes the bug.
Solve My ProblemBig BrainShip It
NomiJ
242mo ago
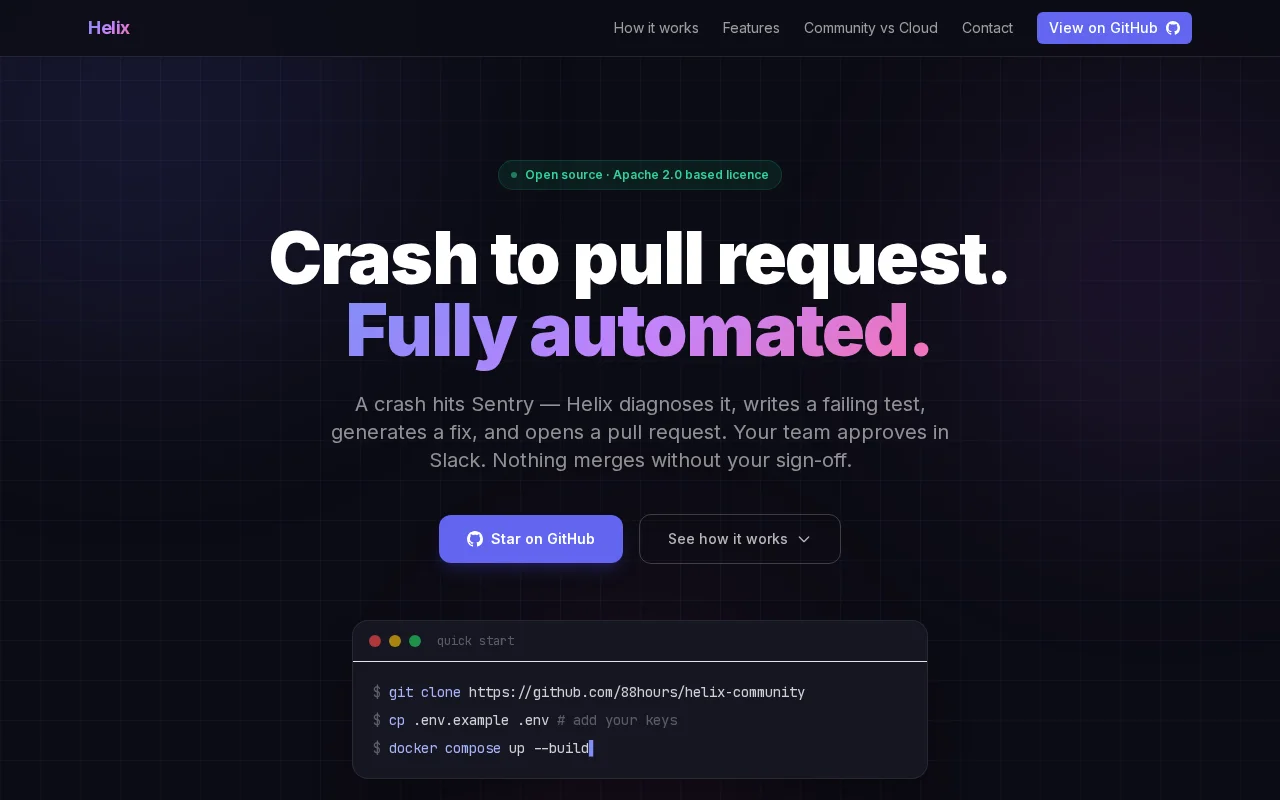
Four-agent pipeline from Sentry crash to PR, but human approval still required.
Engineering teams with production services needing automated incident response
Sentry AI · MutableAI · CodiumAI
1. Crash Handler parses the webhook and extracts context 2. QA Agent follows test driven development approach and writes a failing test then opens a GitHub Issue 3. Dev Agent clones the repo, writes a fix for failing test, and creates a PR. 4. Notifier sends the issue + suggestion to Slack for human review with "Approve PR" or "Reject PR" options.
Built with Python, Redis pub/sub for the event bus, and Claude (or Ollama if you prefer local). Self-hostable via Docker Compose.
GitHub: https://github.com/88hours/helix-community
Happy to answer questions about the agent architecture or how the fix suggestions are generated.
Sentry-to-PR pipeline writes failing tests first, then fixes the bug.
TDD-first auto-fix approach writes failing tests before generating patches, not just patching blindly.
AI daemon hot-patches crashes in 2 seconds—nobody's done self-healing OS like this.
Concrete, hands-on demos — row-level multi-tenancy implemented with Prisma, async jobs via BullMQ/Redis, and tracing through OpenTelemetry/Jaeger — make this a useful reference for people building SaaS backends. It’s not reinventing the stack, but the repo bundles several production patterns and infra pieces together in a way that’s easy to explore; would be stronger with architecture diagrams, runnable quickstart scripts and example data.
Title and broken URL only, no working demo or documentation to evaluate.
Database constraints enforce safety — agent cannot corrupt data even when wrong.