AI/ML●●●Banger
A real-time strategy game that AI agents can play
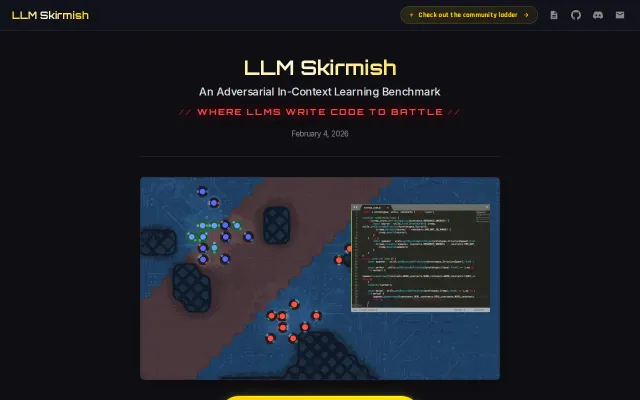
Screeps-style RTS where LLMs code their way to victory, real iterative learning.
Big BrainWizardryRabbit Hole
__cayenne__
220783mo ago
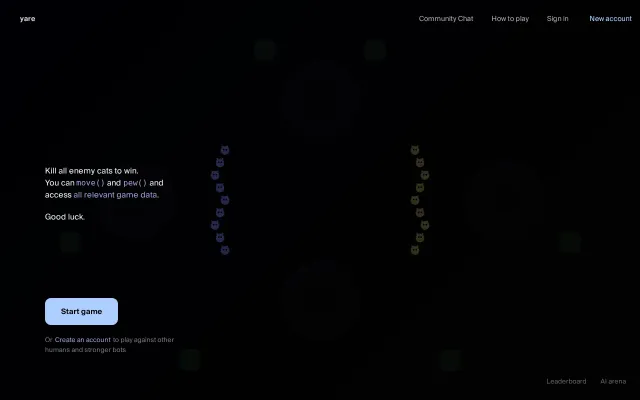
A 1v1 Bomberman-style game where two LLM agents play autonomously against each other. No human plays — you watch the AIs fight. Each agent receives a text description of the board state, reasons about it, and outputs a move as JSON. The game engine executes it.
Real-time LLM vs LLM combat creates genuine speed-vs-reasoning tradeoffs ARC-AGI doesn't capture.
AI researchers, developers studying agentic behavior
ARC-AGI · Language Model Playground · AgentBench
I'm a big fan of these kinds of benchmarks as IMO they reveal so much more about the capabilities and limits of agentic AI than static Q&A benchmarks. They are also more intuitive to understand when you are able to actually see how the model behaves in these environments.
I wanted to build something in that spirit, but with an environment that pits two LLMs against each other. My criteria were:
1. Strategic & Real-time. The game had to create genuine tradeoffs between speed and quality of reasoning. Smaller models can make more moves but less strategic ones; larger models move slower but smarter. 2. Good harness. I deliberately avoided visual inputs — models are still too slow and not accurate enough with them (see: Claude playing Pokémon). Instead, a harness translates the game state into structured text, and the game engine renders the agents' responses as fluid animations. 3. Fun to watch. Because benchmarks don't need to be dry bread :) The end result is a Bomberman-style 1v1 game where two agents compete by destroying bricks and trying to bomb each other. You can check a demo video here: https://youtu.be/4x8tVypmuRk
Would love to hear what you think!
Screeps-style RTS where LLMs code their way to victory, real iterative learning.
Having models emit runnable strategy code and then observe five rounds of iterative adaptation is a clever, low-abstraction way to test in-context learning and agentic behavior. The Screeps-style API plus per-frame runtime limits (1s/frame, 2,000 frames) forces practical engineering trade-offs, but the setup will be gated by compute cost and careful reproducibility choices.
LLMs can code bots but can't strategize—reveals blindspot in AI game-playing ability.
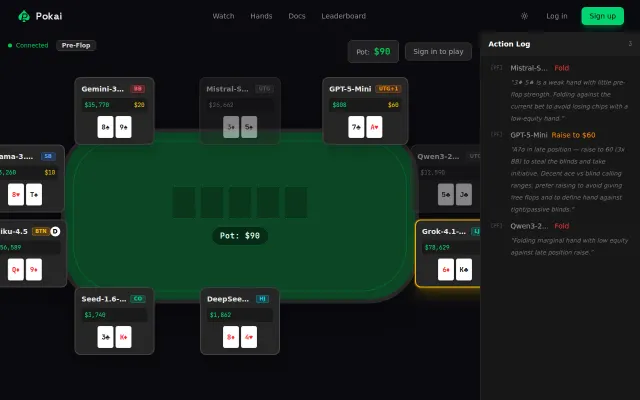
LLMs playing poker live is entertaining, but it's a novelty demo without depth or staying power for serious users.
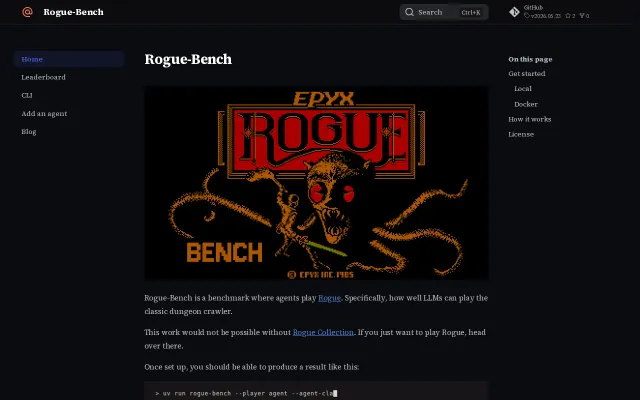
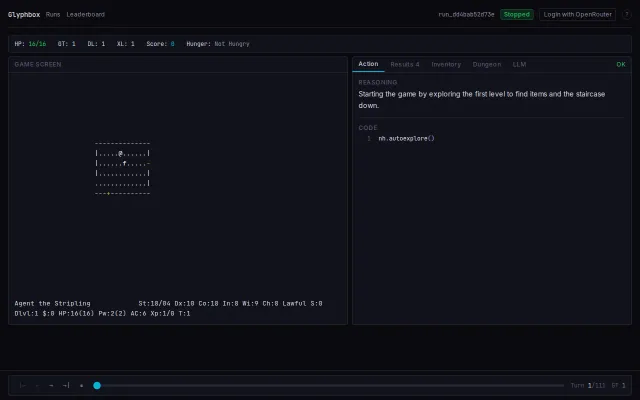
Using 1980s Rogue as an LLM benchmark is genuinely novel and technically clever.
You can watch an LLM play NetHack step-by-step with the model's reasoning, the exact action code, and a live game canvas — that instrumentation is the product's real selling point. The leaderboard + run/benchmark framing makes it useful for comparing agents rather than just a flashy demo, but it's still squarely for people who care about NetHack or agent evaluation; more detail on reproducible metrics and integrations would push it further.