Productivity●●Solid

Guten – Android ereader for Project Gutenberg's 70k+ free books
Frictionless Gutenberg reader with share-to-import and no account required.
CozyNiche Gem
bethanyhunt
521mo ago
A simple Python wrapper for reading data from Discourse forums
No API key needed for public data, but pydiscourse already exists.
Python developers scraping or analyzing Discourse forum data
pydiscourse · discourse2
I've had to pull data from Discourse forums a few times now, and always had to keep dealing with raw requests.get(), rate-limiting and navigating the returned JSON. Our ecosystem is in Python so I looked if there was already a solution, I found pydiscourse (https://github.com/pydiscourse/pydiscourse), but it requires setting up an API key (a hassle) and only returns raw dicts.
There were good solutions in other languages (like discourse2 in TypeScript) but yeah that wasn't in Python.
This is useful if you don't want to set up an API key, only care about retrieving data (not interacting with the platform) and want something in Python. Also has some basic rate-limiting built in!
Example usage:
from discourse_reader import DiscourseClient client = DiscourseClient("https://meta.discourse.org") topic = client.topics.get(12345) print(topic.posts) print(topic.accepted_answer.cooked)
for topic in client.topics.latest(limit=100): print(f"{topic.views:>6} views {topic.title}")
The Pydantic models are set with extra="allow", so if you use this to hit forums with plugins that have extra fields those won't be dropped.Frictionless Gutenberg reader with share-to-import and no account required.
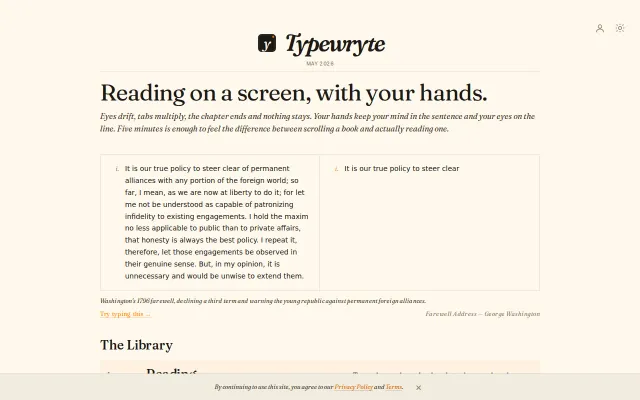
Typing Washington's Farewell Address manually makes you actually read it.
Yet another Pocket clone in a graveyard category after Omnivore shut down.
Solid Rust abstraction for SCSI commands, but existing tools already rip CDs well.
Yet another AI agent wrapper for community management in a crowded space.
Point-and-read without selection beats Natural Reader's click-to-speak workflow.